| Unnamed: 0 | key | fare_amount | pickup_datetime | pickup_longitude | pickup_latitude | dropoff_longitude | dropoff_latitude | passenger_count | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 24238194 | 2015-05-07 19:52:06.0000003 | 7.5 | 2015-05-07 19:52:06 UTC | -73.999817 | 40.738354 | -73.999512 | 40.723217 | 1 |
| 1 | 27835199 | 2009-07-17 20:04:56.0000002 | 7.7 | 2009-07-17 20:04:56 UTC | -73.994355 | 40.728225 | -73.994710 | 40.750325 | 1 |
| 2 | 44984355 | 2009-08-24 21:45:00.00000061 | 12.9 | 2009-08-24 21:45:00 UTC | -74.005043 | 40.740770 | -73.962565 | 40.772647 | 1 |
| 3 | 25894730 | 2009-06-26 08:22:21.0000001 | 5.3 | 2009-06-26 08:22:21 UTC | -73.976124 | 40.790844 | -73.965316 | 40.803349 | 3 |
| 4 | 17610152 | 2014-08-28 17:47:00.000000188 | 16.0 | 2014-08-28 17:47:00 UTC | -73.925023 | 40.744085 | -73.973082 | 40.761247 | 5 |
Introduction
Uber is the current leader in the rideshare market. With millions of people using the platform everyday, the company must prioritize resources to understanding their customer base and how to price their product effectively. This analysis is a simple illustration of the power of bayesian pricing methods for rideshare companies. Specifically, we demonstrate the effectiveness of a basic bayesian linear model at predicting the price of an Uber ride based on our supplied data. Data for this analysis can be found here.
Exploratory Data Analysis
We begin our analysis by viewing the dataset that we will be working with. Below is a simple head method call on our data frame.
Each row is given a unique ID found in the unnamed column. Additionally, we have timestamp information on when the pickup occurred, the pick up coordinates, the dropoff coordinates, and the number of passengers in the ride. All of this information is then given a fare amount. To continue our initial findings, we will call the describe method on the dataframe to see some simple summary stats.
| id | fare_amount | pickup_longitude | pickup_latitude | dropoff_longitude | dropoff_latitude | passenger_count | |
|---|---|---|---|---|---|---|---|
| count | 2.000000e+05 | 200000.000000 | 200000.000000 | 200000.000000 | 199999.000000 | 199999.000000 | 200000.000000 |
| mean | 2.771250e+07 | 11.359955 | -72.527638 | 39.935885 | -72.525292 | 39.923890 | 1.684535 |
| std | 1.601382e+07 | 9.901776 | 11.437787 | 7.720539 | 13.117408 | 6.794829 | 1.385997 |
| min | 1.000000e+00 | -52.000000 | -1340.648410 | -74.015515 | -3356.666300 | -881.985513 | 0.000000 |
| 25% | 1.382535e+07 | 6.000000 | -73.992065 | 40.734796 | -73.991407 | 40.733823 | 1.000000 |
| 50% | 2.774550e+07 | 8.500000 | -73.981823 | 40.752592 | -73.980093 | 40.753042 | 1.000000 |
| 75% | 4.155530e+07 | 12.500000 | -73.967154 | 40.767158 | -73.963658 | 40.768001 | 2.000000 |
| max | 5.542357e+07 | 499.000000 | 57.418457 | 1644.421482 | 1153.572603 | 872.697628 | 208.000000 |
The id column (formerly the unnamed column) indicates that there are about 2 million rows of data. Viewing the fare_amount column, we see that there are some invalid values (fares < 0) and some potential outliers in fares (max is 499). The coordinates can be ignored in this method. Reviewing the passenger_count column, we see that on average there is 1 rider. However, this summary reveals that passenger_count also has potential outliers (max 208 passengers). While we will not include all details of how the dataframe is cleaned, we will mention a few in this analysis. Those who wish to see the full cleaning process can view the github repo where this analysis is housed.
To continue with our exploratory analysis, we first look at how fares have changed over time. Figure 2.1 shows the change over time of fares.

From Figure 2.1, we see that there are a few large spikes but that the majority of the dataset is below \$100. Additionally, we see that the average fare for an Uber ride has risen from \$10 to \$13 over the 6 year dataset. Accounting for large outliers in fares will be an important piece of data cleanup for us.
To continue our investigation, we can plot out the average fare by the time of day as well as the number of rides in the same timeframe. Below in Figure 2.2, we this result.

Figure 2.2 shows that the average fare is relatively constant with exception to the early morning (about 3am-6am with highest peak at 5am). Contrastingly, the number of rides by hour shows that 5am is one of the least popular time to get a ride. The majority of rides appear to be towards the afternoon/evening. The peak at 5am makes more sense seeing how the 5am time has a lower sample, thus skewing the average towards extremes.
Since we have data on location, we can plot the latitude vs longitude to see where these pickups and dropoffs occur. Figure 2.3 illustrates this principle.
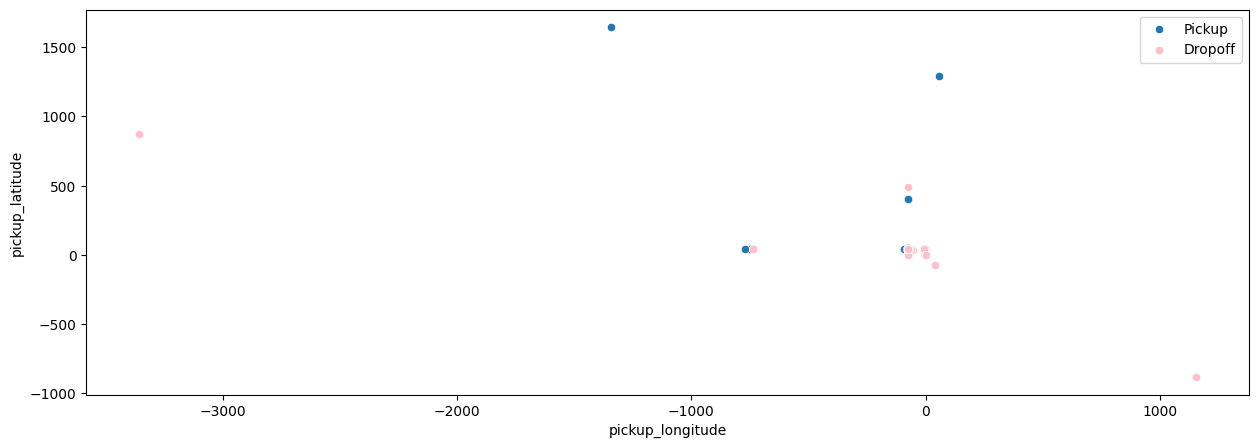
Due to the spread of location in our dataset and possible repeat locations, there aren’t too many dots recorded on the plot. We will need to ensure that these points are realistic locations in our dataset as we strive to model pricing of fares for these trips.
Having raw location data won’t serve our modeling purposes (or at least won’t be as easy to use). To extract the necessary information from these location data points, we will use the haversine distance formula to calculate the distance in miles between each pickup location to each respective dropoff location.
After having performed this distance calculation, we can plot the relationship between distance of trip in miles and fare amount for said trip. Figure 2.4 shows this relationship.
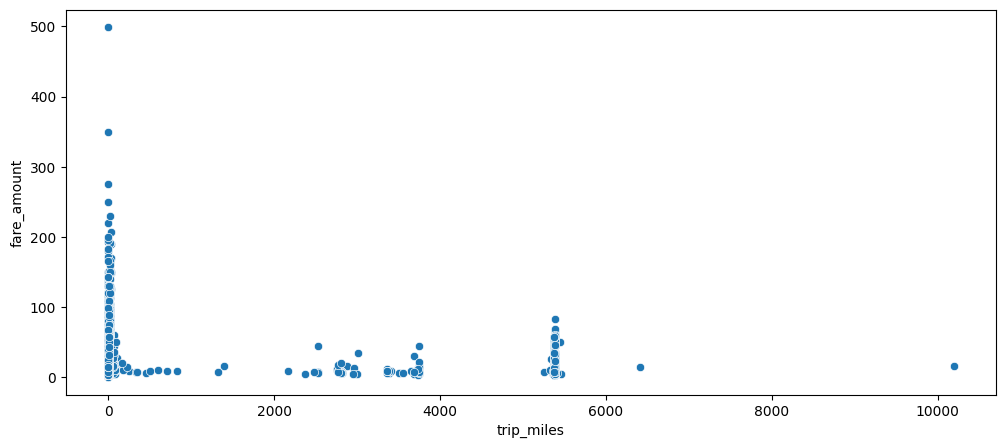
We see that the great majority of trips are close to 0 with a wide range of their respective fare amounts (max of 500). Additionally, we see that there are a few outliers of super long trips (greater than 2000 miles!). I for one would not want to be an in Uber for 10000 miles and can’t imagine where someone would even drive to for 10000 miles. We will address these errors in the data later on in the analysis.
To confirm that these outliers are truly outliers, we can plot the distribution of miles per trip and fare amount per trip. This is shown in Figure 2.5.
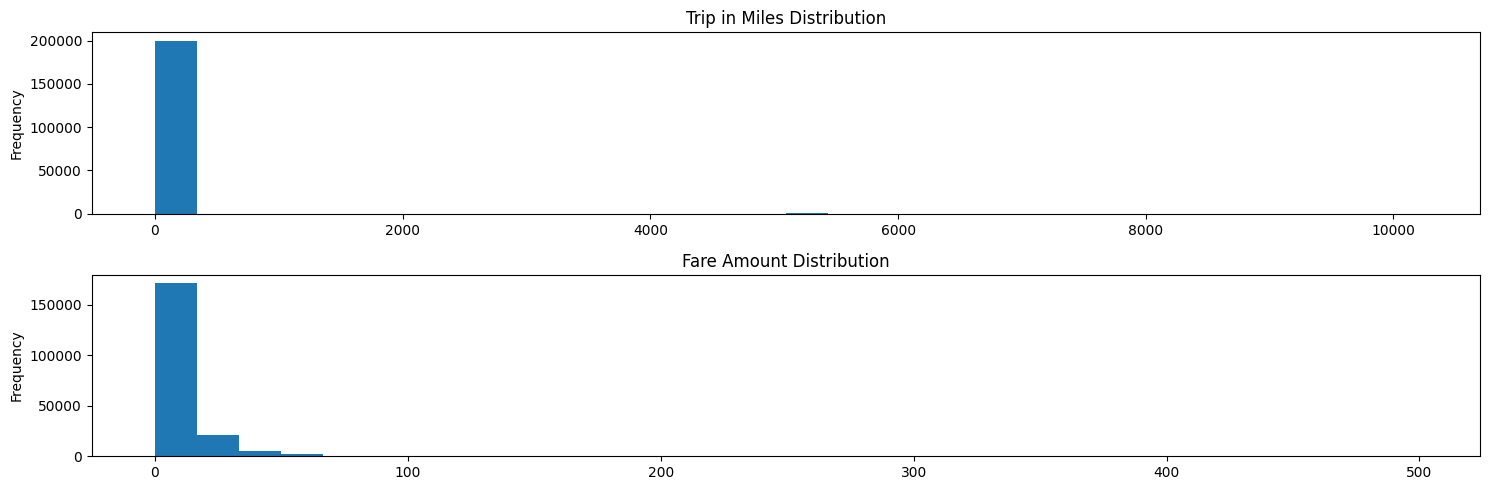
To solidify our findings, we view one more graph in Figure 2.6.
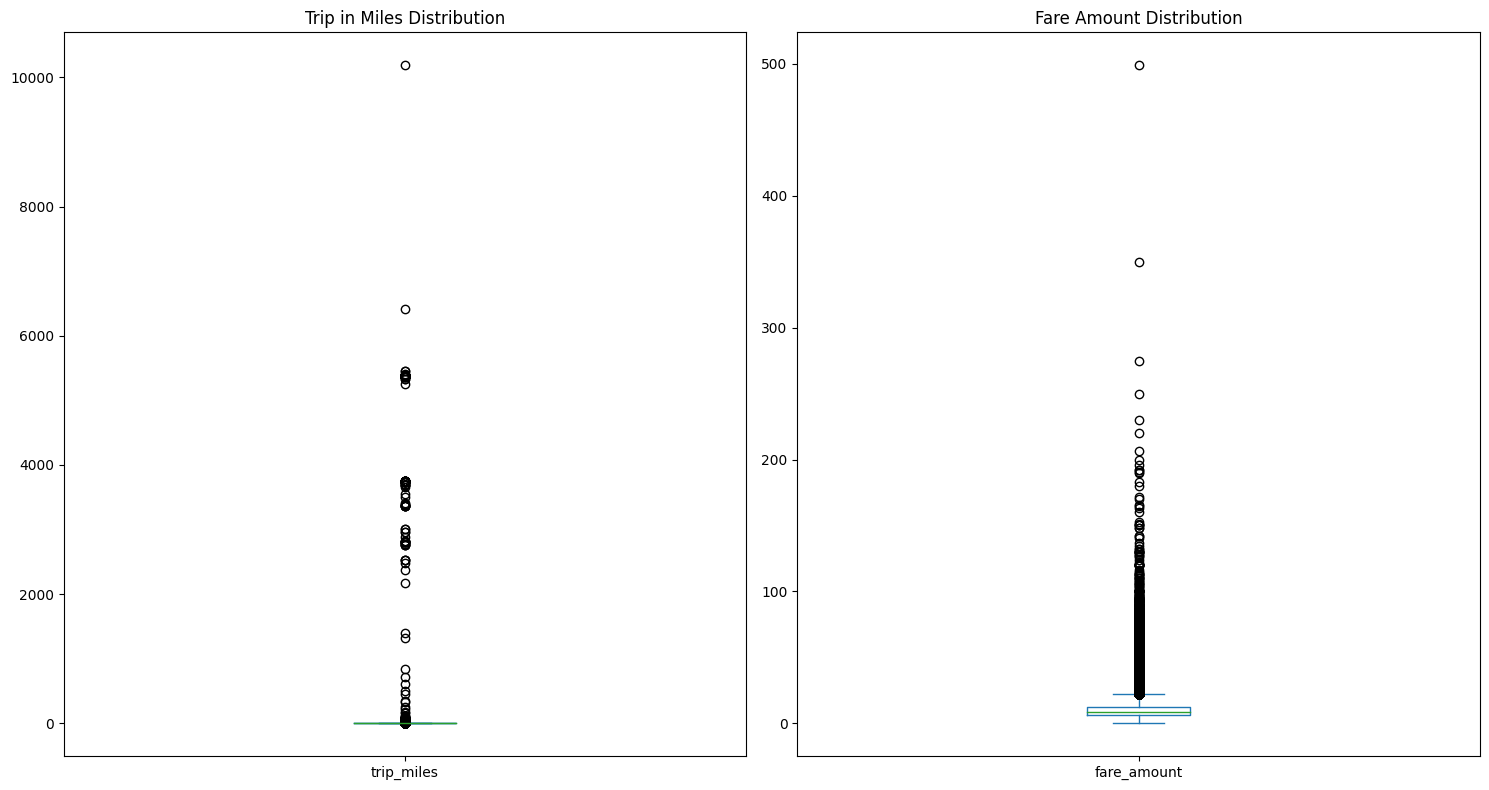
Both Figure 2.5 and Figure 2.6 confirm that there are many outliers that need to accounted for in our model. In this analysis, we will remove these outliers since we have sufficient sample size without them. From our calculations, we decided to remove all observations with fare amounts greater than \$30, trips with distance in miles greater than 10 miles, and there needs to be at least 1 passenger.
Investigating Relationships with Fare Amount
As stated earlier, the purpose of this analysis is to analyze what, if anything, have effects on fare amount. We further this exploration in Figure 2.7 where we check the distribution of fare amount by the passenger count.
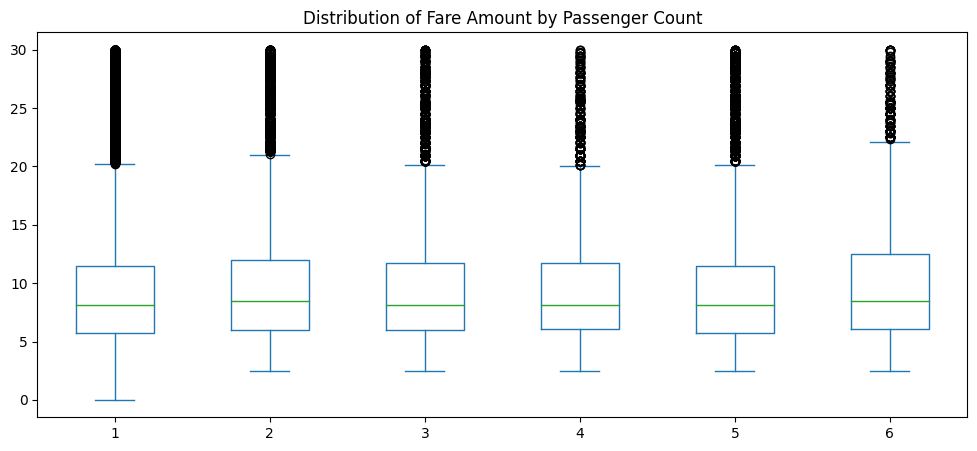
As we can see, the distributions among passenger count appear to be approximately the same. The median fare amount for each passenger count appears to be constant and each quartile appears to be relatively equal to the others.
Another possible influence could be day of the week when a ride is taken. Figure 2.8 shows the respective distributions of fare amount by weekday and weekend.

Just as we saw in Figure 2.7, Figure 2.8 shows that there is not much difference between weekday and weekend trips with regard to fare amount.
After having cleaned up our dataset, we can view a scatterplot of trip in miles vs fare amount, colored by weekend or weekday, to see the relationhsip between these variables. This is shown in Figure 2.9.
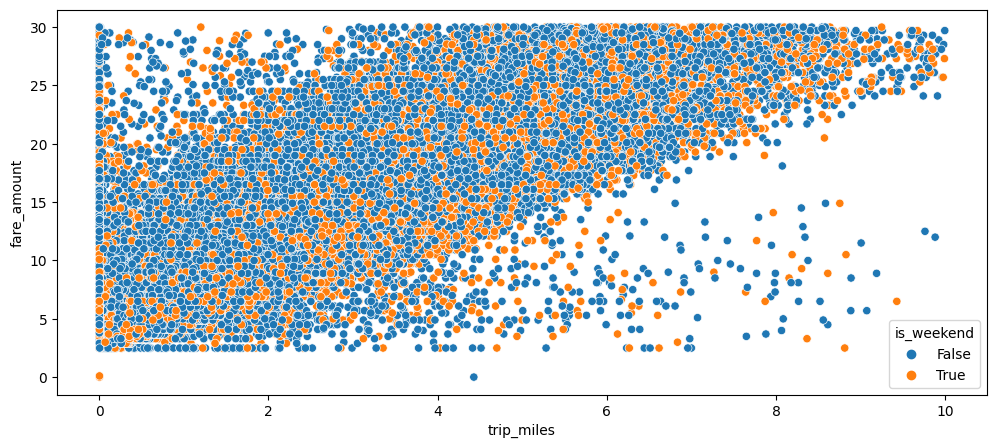
Even after our data cleanup, we see in Figure 2.9 that there is a large amount of data to still use. There appears to be a slight positive linear relationship between trip in miles vs fare amount. We will hope to quantify this when we build our model. There also appears to be a lot more rides during the week vs the weekend (which makes sense since there are more weekdays than weekends).
Check for Differences in Number of Rides by Hour
As we mentioned at the end of the previous section, there are more rides on weekdays vs weekends. We should continue to explore the difference in these different segments. First, we’ll explore the difference in the number of rides by hour, split by weekdays vs weekends. This is shown in Figure 2.10.
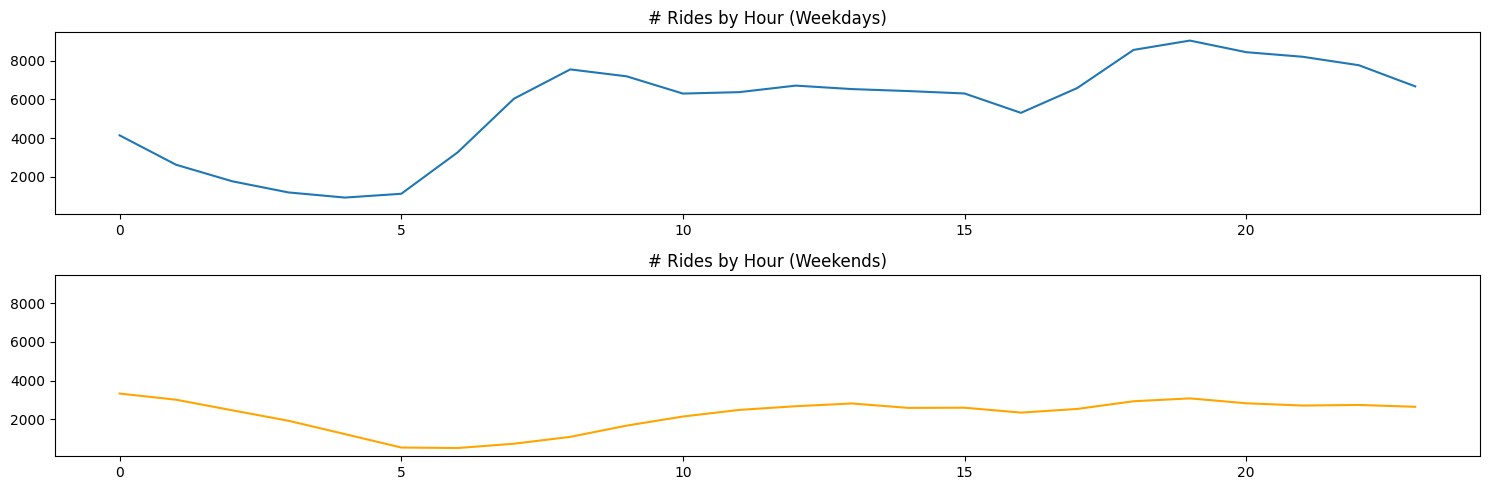
As we can see, although the total number of rides might differ between weekdays and weekends, the trend appears more or less the same. Weekdays have much heavier peaks around the usual rush hour commuting times. Weekends appear to steadily increase from morning to evening.
While weekdays vs weekends are one possible segmentation for number of rides, seasons are also a potential group we should explore for delineations in number of rides. Figure 2.11 shows the number of rides by hour for each season.
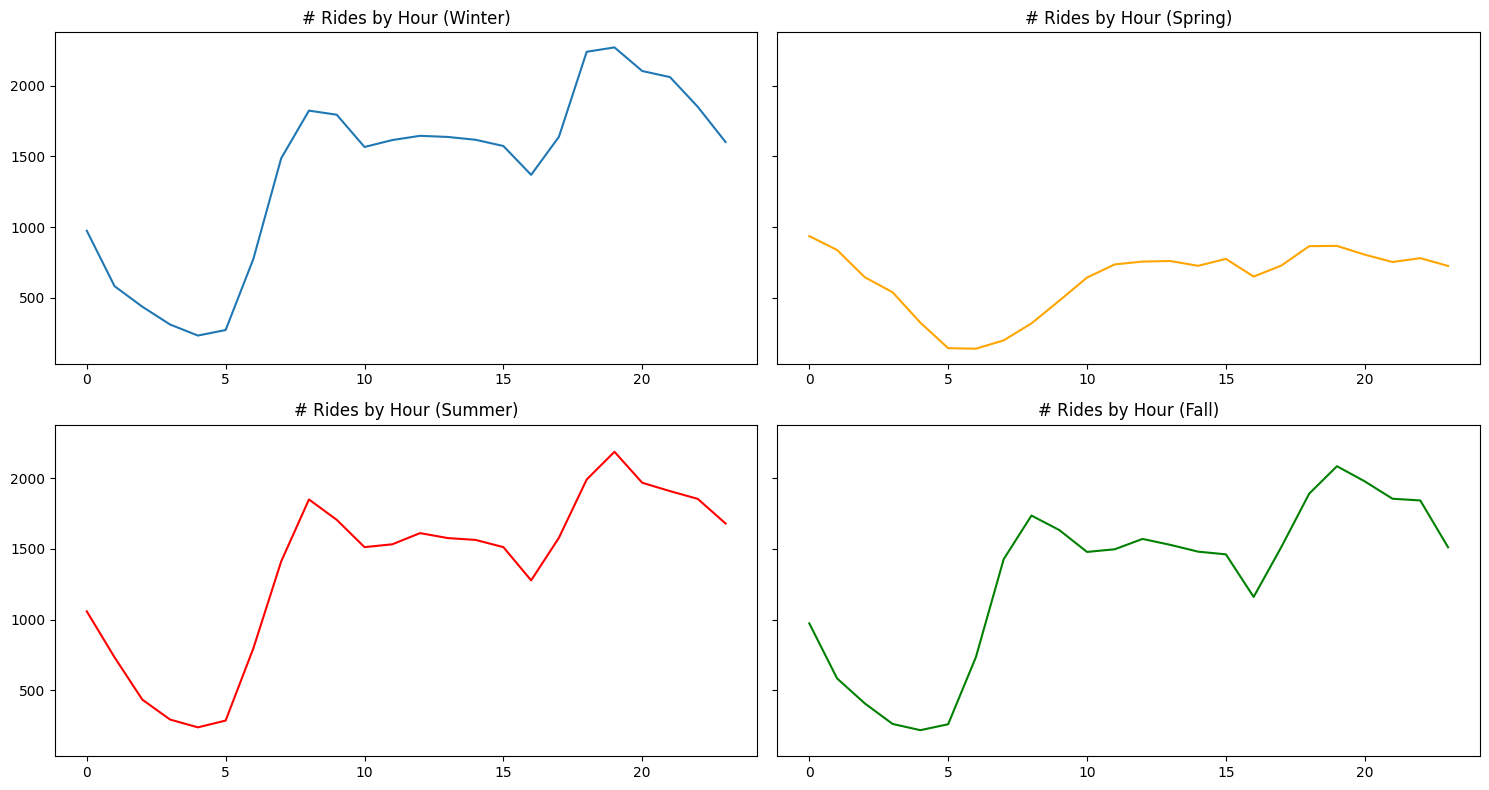
There does not appear to be any differences between seasons, except for spring having very low peaks in comparison to the other 3 seasons. Generally speaking, each season follows the same trend of number of rides by hour, with winter, summer, and fall each following very similar trends and numbers.
Fare Amount by Time of Day and Season
We return to investigating fare amount since that is the principle objective of this analysis. One relationship we have yet to explore is the fare amount in relation to time of day. To do this, we will bucket each hour into a specific time of day (ie morning) and calculate the distributio of fare prices at that respective time. Figure 2.12 shows this distribution.
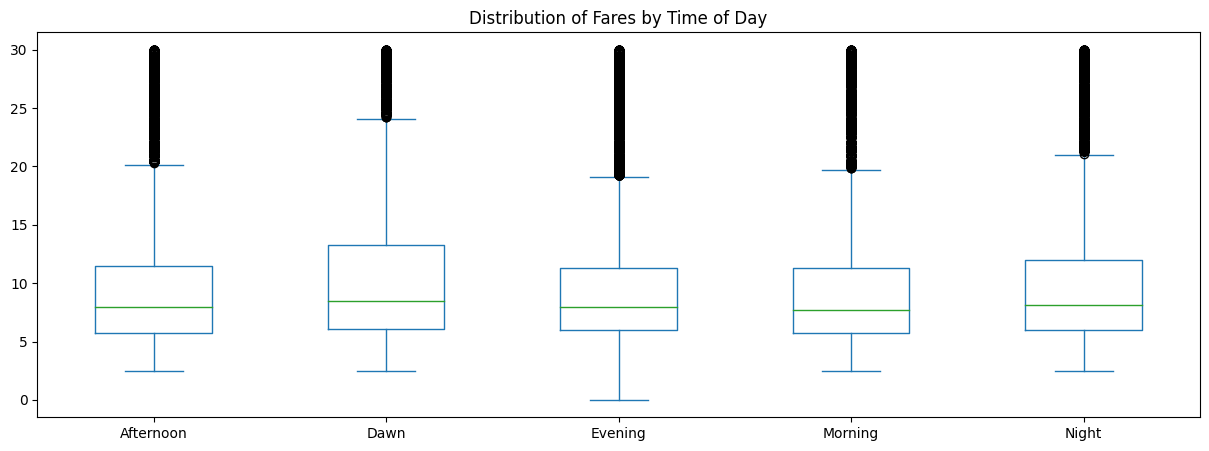
From Figure 2.12, we see that there is no real difference in distributions. Dawn appears to have the highest variance of the 5 time buckets, but does not appear to be significant.
To combine some of the relationships we have explored thus far, we will look at the change in average fare, split by season and time of day. Perhaps a combination of these segments could show a possible difference in fare price. Figure 2.13 shows this relationship.
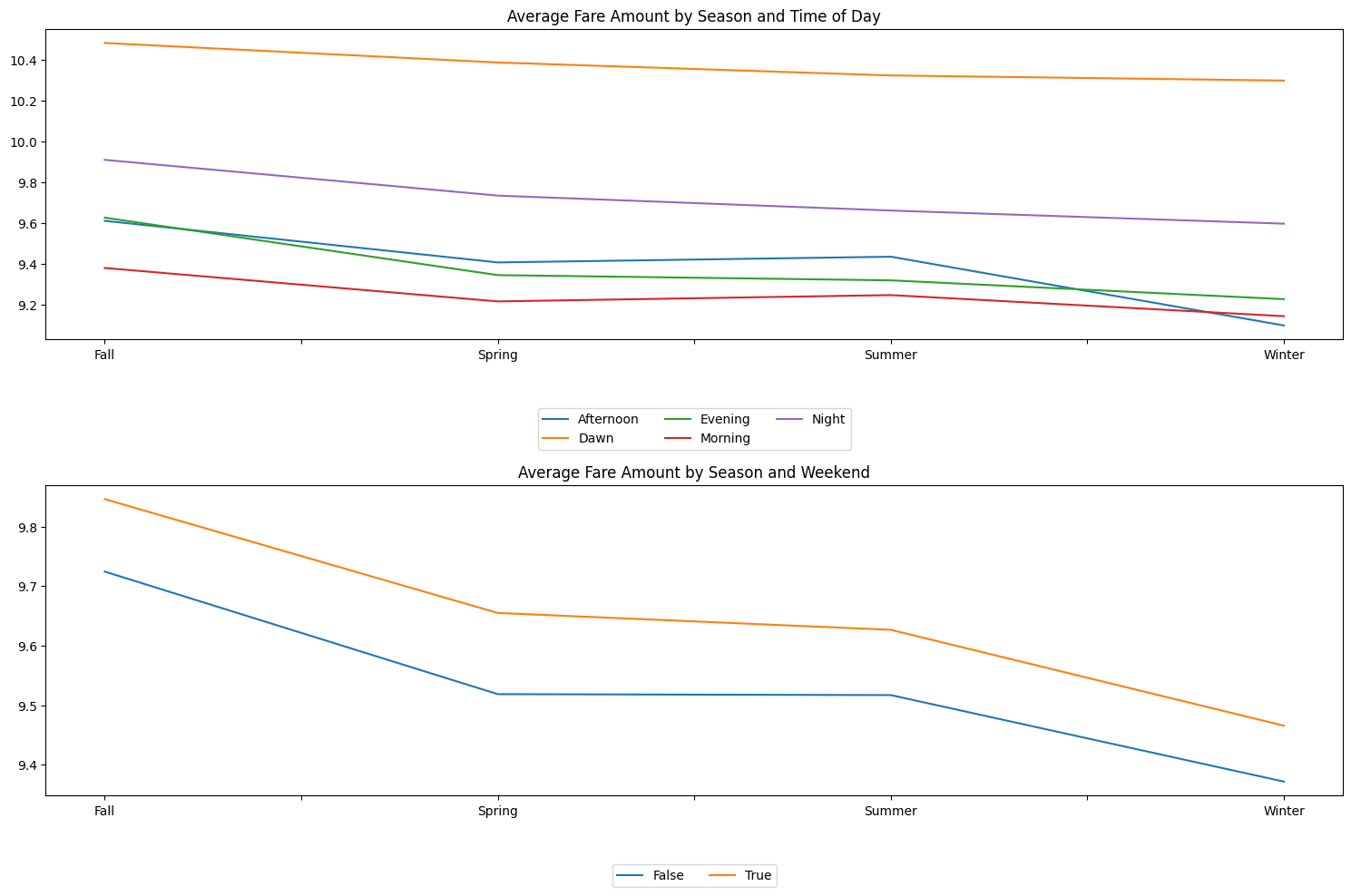
Figure 2.13 is very informative as it shows clear delineations between average fare prices. The top panel shows that dawn by far has the highest average fare price over the other 4 time of day buckets. The closest to each other are evening and afternoon across all seasons. Interestingly, afternoon has a sharp dip in average fare price in the winter. The average afternoon fare price in winter is the lowest, followed closely by morning and evening. While we do notice clear separation between these lines, we should recognize that these prices are within essentially a dollar a part.
The bottom panel of Figure 2.13 shows a clear (yet small in dollar value) difference between weekend and non-weekend average fare amounts across seasons. Weekends on average have a higher fare amount than weekdays across all seasons. Additionally, The difference appears constant between the average fare amount of weekends and weekdays across all seasons. Figure 2.13 shows the usefulness of these features in helping the model capture defined segments across the data.
Bayesian Modeling
After having explored the data, the next step is to write out our model to identify how we will model the effect of certain features on the response variable of fare amount. A flexible and useful model to do this is a linear regression model. To do fit this model, we will need to list the variables x_i that we will use to explain our response y_i. Our written model is found below.
Y_{i} = \beta^{T}x_{i} + \epsilon_{i} \epsilon_{i} \sim \text{i.i.d. } N(0, \sigma^{2})
Each observation of fare amount is modeled as a linear function of explanatory variables times beta values, plus our error term \epsilon_{i} to account for variantion in the data. The explanatory variables we chose to use for this analysis are the following: passenger count, trip_miles, is_weekend, season_spring, season_summer, season_summer, time_day_dawn, time_day_evening, time_day_morning, time_day_night. Notice that season_fall, is_weekday, and time_afternoon are not included in the explanatory variable list. These values are included in the model, but are set as the baseline of the model. Essentially, our \beta_{0} value will represent a beginning point for the change in fare amount for a trip in fall, on a weekday, in the afternoon. All other \beta values will be modeled as either additions to or deductions from this baseline value.
Additionally, since this is TheBayesianBandit blog, this will be a bayesian analysis and subsequently, require that we write out priors for our parameters of interest and derive a posterior distribution for these. Below is the bayesian addition to our model approach.
\theta = (\beta_{0} ... \beta_{p-1}) Y \sim MVN(X\beta, \sigma^{2}) p(\theta) \sim N(0, 3) p(\sigma^{2}) \sim IG(3, 1) p(\theta|D) \propto p(\theta)p(D|\theta)
Our primary parameter of interest in this study is the parameter \theta, which is a vector of \beta values corresponding to each explanatory variable in our dataset. We propose that fare amount is modeled by a multivariate normal distribution with mean X\beta and variance \sigma^{2}. \theta is proposed to be distributed normally with mean 0 and standard deviation of 3. \sigma^{2} is proposed to be distributed by an inverse-gamma distribution with \alpha = 3 and \beta (rate beta, not LR beta) = 1. Utilizing these values, we derive the posterior distribution for \theta based on the data updates from our model. To do this, we will utilize a NUTS sampler with 1000 warmup samples and 2500 samples. Furthermore, we have split our data into train-test splits, with 67% of the data belonging to training and 33% belonging to testing. The results of our sampler are found below.
mean std median 5.0% 95.0% n_eff r_hat
beta[0] 4.69 0.03 4.69 4.65 4.73 1296.49 1.00
beta[1] 0.05 0.01 0.05 0.04 0.06 4623.29 1.00
beta[2] 3.25 0.01 3.25 3.24 3.26 3806.85 1.00
beta[3] -0.26 0.02 -0.26 -0.29 -0.23 3442.71 1.00
beta[4] -0.22 0.02 -0.22 -0.26 -0.19 1632.68 1.00
beta[5] -0.34 0.02 -0.34 -0.38 -0.31 1502.49 1.00
beta[6] -0.26 0.02 -0.26 -0.29 -0.22 1710.00 1.00
beta[7] -1.00 0.03 -1.00 -1.04 -0.95 1962.38 1.00
beta[8] -0.19 0.02 -0.19 -0.22 -0.15 1530.76 1.00
beta[9] -0.58 0.03 -0.58 -0.62 -0.53 1851.44 1.00
beta[10] -0.78 0.02 -0.78 -0.82 -0.74 1941.79 1.00
sigma 7.35 0.03 7.35 7.31 7.41 5336.50 1.00
Number of divergences: 0As we mentioned earlier in this section, our \beta_{0} represents our baseline distribution for fare amount for a trip taken in fall, on a weekday, in the afternoon. On average, this value is about 4.69. Our 95% credible interval indicates this would be anywhere from 4.65 to 4.73 with 95% probability.
It is interesting to not that the only increase in fare amounts come from \beta_{1} and \beta_{2}, which are the changes in fare amount based on the value of number of passengers and trip in miles, respectively. On average, for every 1 mile increase in the trip, the fare amount goes up by 3.25 dollars. Conversely, for trips taken in at dawn (\beta_{7}), this results in an average decrease of 1 dollar from the fare amount.
In order to know if we can trust these numbers, we need to check the n_eff values, the r_hat values, and the trace plots for each beta in order to verify that each parameter has converged and each parameter has achieved good mixing. Above, we see that each parameter achieved a r_hat value of 1, which indicates convergence. The n_eff value shows the effective sample size for each parameter and since each value is a good ratio with regard to the number of samples we drew with our sampler, this is also verified. Below in Figure 3.1 we analyze the trace plots for each beta value.
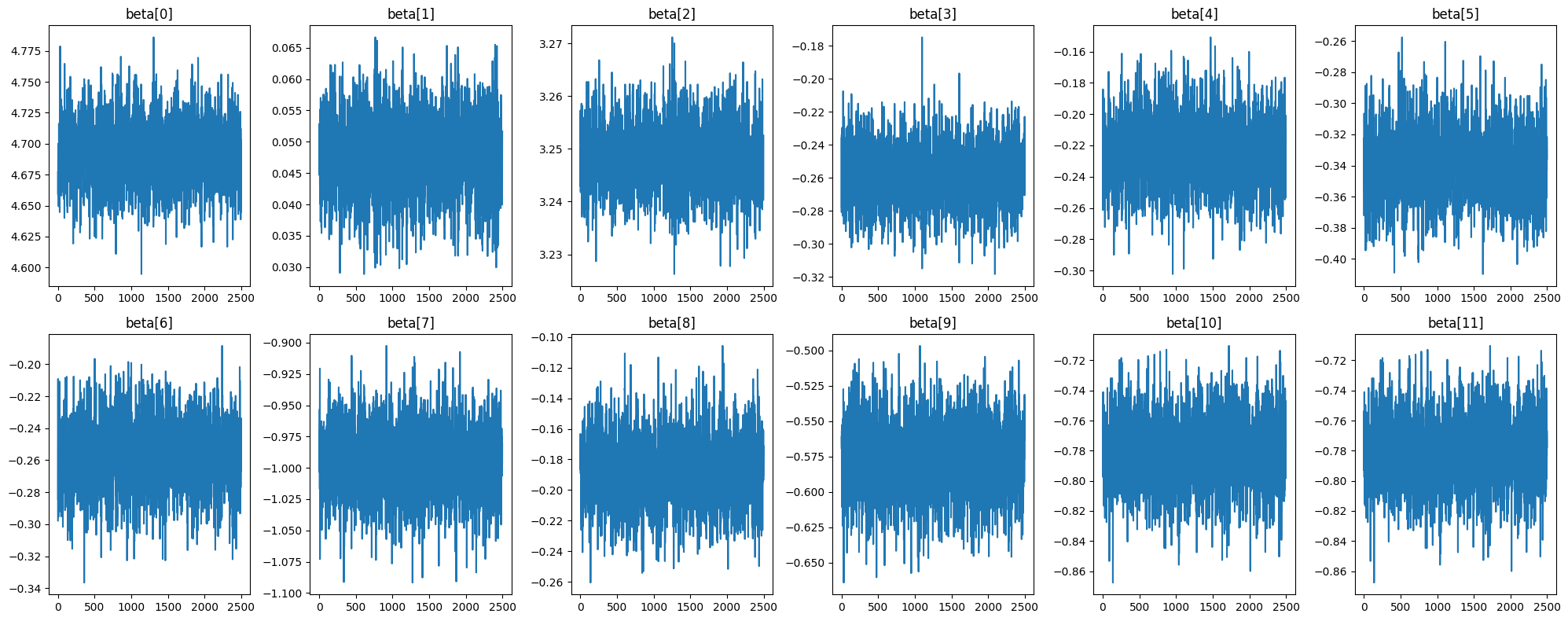
Figure 3.1 shows that each beta value appears to have good mixing and has achieved an acceptable level of stationarity. We will proceed with the analysis trusting in the numbers generated from our sampler. We can now proceed to view the posterior distribution of each beta value from our model. This is shown in Figure 3.2.
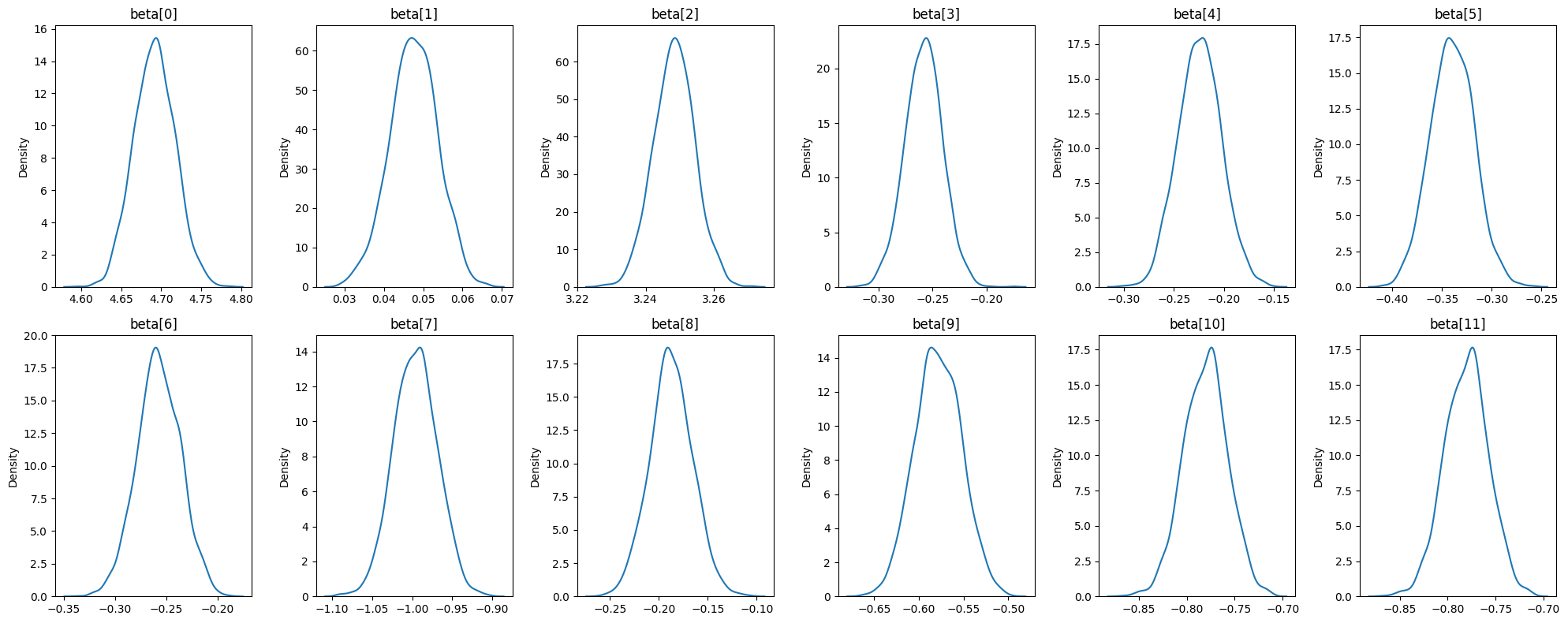
Figure 3.2 shows that each beta value is sharply peaked with very little variation from the mean. As mentioned previously, all beta values along their entire distribution appear to have a negative impact on fare amount, with exception to beta[1] (number of passengers) and beta[2] (trip in miles). It is worth noting that while some values are close to 0, none of them ever cross the 0 threshold.
Now that we have a posterior distribution for each beta value, we can generate predictions from our test set. Our values for RMSE, coverage, and width are shown below.
RMSE: 1.84
Coverage: 0.02
Width: 0.10On average, our predictions are off by about 1.84 dollars. Comparing this value to the standard deviation of the fare amount distribution (5.17), this is a good sign that our model has good predictive power. Unfortunately, our coverage does not score well with only 2% coverage over the test set. However, this is not too bad of a loss, since the width of these intervals are usually around .10. Since the width of these predictions are so narrow, it is normal to have low coverage. Nonetheless, we should investigate ways to improve coverage so that our predictions always lie within our 95% PIs.
Simple Prediction Demonstration
To demonstrate how our model predicts, we will make a prediction for a single passenger, riding 5 miles, in the winter, in the morning, on a weekday. Using our estimated beta distributions above, we obtain the posterior predictive distribution in Figure 3.3.
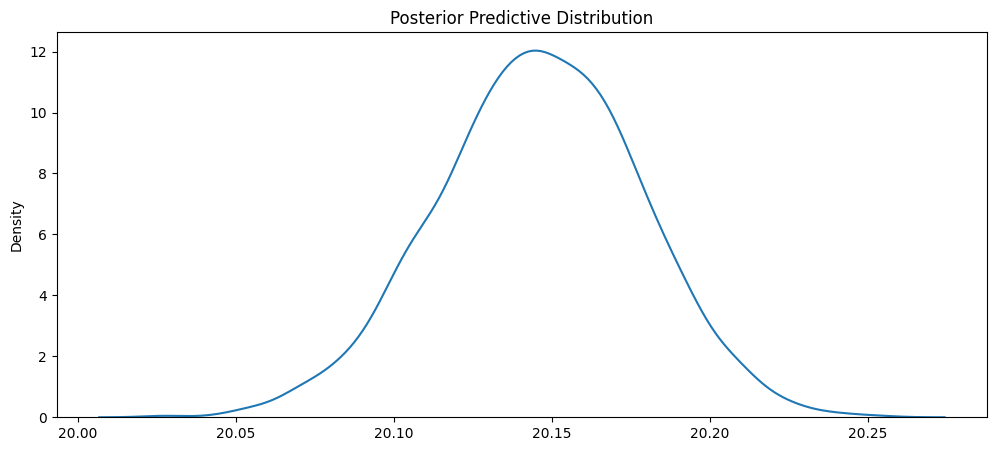
From Figure 3.3, it appears that the average fare amount for a ride like this would be around 20.15 dollars. Approximate 95% PI would be (20.10, 20.20). Our model makes very precise predictions as evident by the short width of the distribution. Nonetheless, this illustrates very well how our bayesian linear model makes a predictive distribution instead of just a single point estimate. We have a small amount of uncertainty around this estimate due to the large amount of training data.
Conclusions
We demonstrated very briefly in this analysis the abililty to analyze ride share data by extracting meaningful featrues form raw form. We showed that there were reasonably viable features to use to understand how fare amount is estimated. We built a bayesian linear model that calculates the effect of each feature on fare amount, showing uncertainty with each estimate based on each value’s posterior distribution. We reviewed the predictive capabilites of the lienar model by estimating metrics like RMSE and coverage. While RMSE proved to be low, coverage also was very low due to the small widths of our posterior predictive distributions. Further enhancements to the model can be made, such as incorporating interactions, engineering new features from the raw data, or utilizing a different sampler/different numbers for different results. Overall, we are pleased with the results of our model. We have succesfully crafted a model that predicts fairly well the fare amount for rides on Uber.