| store_id | day_num | has_mobile | perc_rev_member | |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0.412567 |
| 1 | 0 | 1 | 0 | 0.299284 |
| 2 | 0 | 2 | 0 | 0.465392 |
| 3 | 0 | 3 | 0 | 0.190485 |
| 4 | 0 | 4 | 0 | 0.647600 |
Abstract
Drive-thrus are the American way of dining. Therefore, companies need this part of the restaurant to operate at peak efficiency. One company in particular that excels in this is Chick-fil-A. Recently, Chick-fil-A has begun testing mobile-thrus, a designated drive-thru lane for mobile orders made through the Chick-fil-A app. In this post, we briefly review the history of the drive-thru for fast food restaurants. We further zoom in on Chick-fil-A’s drive-thru strategy and operations. We then present an experimentation design for Chick-fil-A to validate this drive-thru pilot program using Synthetic Difference-in-Difference (SDiD). We conclude by discussing possible strategic directions from our causal findings.
Introduction
Although the drive-thru is a necessity for many fast-food chains today, it was not initially seen as a revolutionary concept. The first drive-thru is credited to Red’s Giant Hamburger, a small restaurant in Missouri, in 1947 [1]. The innovation’s primary motivation was to transition from the traditional drive-in model to a faster system, allowing cars to pull up to a service window and leave promptly after receiving their food.
Word of the drive-thru model eventually spread to the West Coast, where burger chain In-N-Out operationalized and advanced the concept. In-N-Out innovated by inventing the two-way speaker system, which separated order placement from food pickup to speed up operations. Soon after, other chains like Jack in the Box and Wendy’s adopted this two-way speaker drive-thru model. Despite this growing trend, larger chains such as McDonald’s and Burger King did not implement their own drive-thrus until the mid-1970s. Today, drive-thrus are critical to the success of fast-food chains, estimated to generate approximately 62% of all revenue [2]. This places immense pressure on companies to meet the high expectations of the drive-thru model: speed, efficiency, and accuracy.
Chick-fil-A
In 1946, brothers S. Truett Cathy and Ben Cathy opened the Dwarf House in Hapeville, Georgia [3]. The establishment was a typical diner, serving a variety of items like burgers, fries, and shakes. To differentiate the menu, S. Truett Cathy began experimenting with boneless chicken sandwich recipes. He eventually found the perfect combination, and the new sandwiches quickly became more popular than the burgers. Cathy decided to focus exclusively on this signature chicken sandwich and coined the name Chick-fil-A to reflect its high quality (inspired by the premium beef cut, fillet). The first official Chick-fil-A restaurant opened in Atlanta, Georgia, in 1967.

The first drive-thru Chick-fil-A opened in Greenville, South Carolina, in 1993. Since then, Chick-fil-A has grown into a fast-food powerhouse, generating approximately $8 billion in annual sales. A significant portion of this revenue is attributed to its drive-thru operations.
Chick-fil-A wasn’t always known for its fast drive-thru service; in fact, it was once one of the slowest chains in the country. However, through a combination of strategic operational changes and technological innovations, the company has since become the industry standard for drive-thru efficiency.
Drive-Thru Operations
In practice, drive-thru operations at each Chick-fil-A location are not identical; they vary based on factors like store layout and local demand. For this analysis, we will assume a standard operational structure and flow as depicted in Figure 1, which serves as a representative model for our discussion.
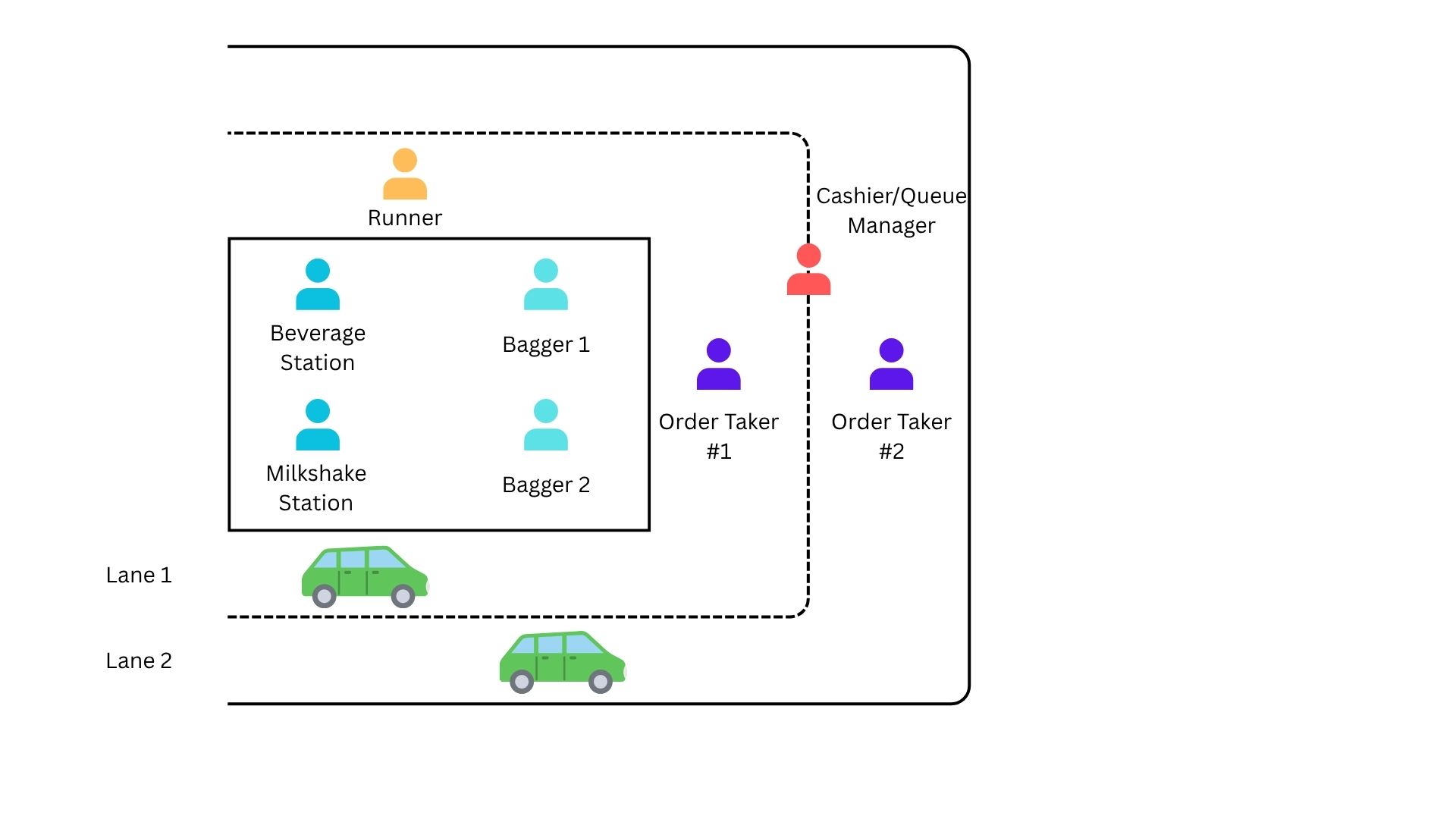
Our Chick-fil-A restaurant, as shown in Figure 1, features a double-lane drive-thru. The process is as follows:
- A car enters the drive-thru and chooses a lane.
- The customer places their order with the designated order taker for that lane.
- If paying with cash, the customer stops at a shared cashier station located between the two lanes.
- The car proceeds to the delivery window, where an employee delivers the food.
Inside the restaurant, a team of baggers and beverage/milkshake station employees assemble the orders based on their contents.
Analyzing the Drive-Thru via Queue Theory
Our drive-thru operation can be analyzed using tools from queue theory [4]. Below are some key parameters.
- Arrival Rate (\lambda): The average rate of customers arriving at the drive-thru. In our scenario, \lambda = 2 customers per minute.
- Order Take Time (OTT): The average time it takes for customers to place their order. In our scneario, OTT = 30 seconds.
- Service Rate (\mu): The average rate at which orders are processed and fulfilled (time from order placement to order delivery). In our scenario, \mu = 2.33 customers per minute.
With two order takers and a single service window, the system’s bottleneck is the service window, as it has the lowest service rate. Since the overall system’s throughput is limited by this single service point, we can model the entire drive-thru as a M/M/1 queue using Kendall notation [5], where the service window represents the single server. This simplifies our analysis by focusing on the primary constraint on the system’s capacity.
For our drive-thru to run efficiently, we want to ensure that certain key metrics are optimized. These metrics and the respective calculations are listed below.
- System Utilization (\rho): \rho = \frac{\lambda}{\mu} = 85.8\%
- Average Number of Customers in Queue (L_{q}): L_{q} = \frac{\lambda^{2}}{\mu(\mu - \lambda)} = 5.2
- Average Time in Queue (W_{q}): W_{q} = \frac{L_{q}}{\lambda} = 2.6 \text{ mins}
- Average Number of Customers in System (L): L = \frac{\lambda}{\mu - \lambda} = 6.1
- Average Time in System (W): W = \frac{1}{\mu - \lambda} = 3.0 \text{ mins}
Under the current system, the service window operates at around 86% capacity. On average, there are 5 cars waiting for their food, with each car spending an average of 2.5 minutes in the queue. The total average time a car spends in the system—from entering the drive-thru to receiving their food—is 3 minutes, with a total of 6 cars in the system on average. Overall, for peak hours, these are acceptable values that represent an efficient drive-thru.
Chick-fil-A One
In 2012, Chick-fil-A released their own mobile app. This app allowed customers to order items from their mobile device and pick up their order in the lobby or via the drive-thru. In 2016, Chick-fil-A added an incentive to get the app by developing their Chick-fil-A One rewards program. Any customer could now sign up and earn rewards for their purchases through the app.

As shown in Figure 3.2, customers earn points based on their spending tier, with higher tiers offering greater benefits. This program is not only valuable to customers but also immensely beneficial to Chick-fil-A. In exchange for these rewards, the company collects crucial data on customer purchasing habits. This data can reveal insights into a customer’s typical order time, their distance to the store when placing an order, purchasing trends on weekdays versus weekends, etc. These data points allow Chick-fil-A to personalize the customer experience and optimize store operations.
Mobile Thru
While members can place orders on the app for drive-thru pickup, these orders are currently not given priority. The system processes them like any other order in the queue. The only difference is the speed of order taking. A customer simply provides their name to an order taker, who then adds the pre-entered mobile order to the queue.
Since drive-thrus are the most popular way for customers to order their food and Chick-fil-A wants to continue to encourage customers to use their app, Chick-fil-A came up with “mobile-thrus”. Here, customers who use the mobile app have a dedicated lane in the drive-thru instead of joining the normal queue mixed with mobile and non-mobile customers.

We can view how this would affect the operations outlined in Figure 3.1. Using the same notation as before, we assume that the average OTT remains at 30 seconds. In the new mobile-thru lane, average OTT is 10 seconds. While this is a great improvement in OTT, the bottleneck still occurs at the service window. Instead of dealing with a M/M/2 converging into a M/M/1 queue, we can break this into two parallel M/M/1 queues. The system specifications are enumerated below.
- \lambda_{normal} = 1 customer per minute
- \lambda_{mobile} = 1 customer per minute
- OTT_{normal} = 30 seconds
- OTT_{mobile} = 10 seconds
- \mu_{normal} = 1.1 customers per minute
- \mu_{mobile} = 1.3 customers per minute
In the scenario with the specifications above, we assume the same average arrival rate but split evenly between the two lanes. The key difference is the service rate between the two lanes. We assume that we put the “faster” bagger on the mobile lane to enhance that experience. With these rates, we calculate the following metrics in Table 3.1.
| Normal | Mobile | |
|---|---|---|
| \rho | 90.9% | 76.9% |
| W_{q} | 9.1 | 2.6 |
| L_{q} | ~9 | ~3 |
| W | 10 | 3.3 |
| L | ~10 | ~3 |
As evident in the table, the mobile lane runs at much higher efficiency than the normal lane. On average, the normal line has almost 9 cars in the queue, 3 times as many as the mobile lane. Subsequently, cars in the normal lane wait on average 9 minutes for their order to be completed, whereas the mobile lane only waits about 2.6 minutes.
Testing the Mobile-Thru
While our theoretical model of the drive-thru system clearly indicates that the mobile lane would run faster, the question then becomes: would it actually? Additionally, not only would we like the mobile lane to be more efficient, but we would like more customers to use the mobile lane. From a strategic point of view, if we can encourage more customers to use the mobile lane, we can gather more data and have a much clearer picture of the purchasing behavior of our customers.
Theory Behind Strategy
Our mobile-thru is an application of nudge theory [6], which states that people’s decisions can be influenced by small changes to their “choice architecture.” In this scenario, we alters our drive-thru by changing the lane configuration from two traditional lanes to one traditional lane and one exclusive “mobile-thru” lane. This change in choice architecture, combined with the greater efficiency and rewards associated with the mobile lane, provides a strong nudge for customers to choose the mobile-thru option.
This scenario also is a practical application of social exchange theory [7]. In exchange for exceptional service and loyalty points, we gain valuable customer data. This information includes a range of data points such as demographics, average ticket sizes, redeemed rewards, and the effectiveness of promotions.
Testing Our Theories
From our theories, we can develop research questions from which we will design our experiment. For our analysis, we focus on one primary question: - Does the mobile-thru increase the proportion of mobile orders?
In order to answer this questions, we need to design a robust experimentation framework that will allow us to gather data points to then perform valid causal inference. Ideally, we’d like to perform some kind of randomized controlled trial (RCT). However, this is infeasible since we can’t randomly assign customers to one of the lanes. Furthermore, a wide-scale rollout is too risky, as an unpopular mobile-thru could damage brand credibility and incur significant costs.
To accomdate these requirements, the proposed research design is as follows: - Randomly select n stores in each of our core geographic regions - Perform a staggered roll out of the mobile-thru to the n locations - For each roll restaurant, collect transcation data t_{1} number of days before roll out and t_{2} days after roll out - Compare the transaction data between “treated” stores and “non-treated” stores
Note: We perform random selection of restaurants to mitigate the potential for confoundness. We also perform a staggered roll out for the same reason (perhaps economic conditions are better in one month vs another).
Exploring the Data
We begin exploring the data by first seeing what data we have available. We call a simple head method call to preview the data.
We have four columns currently. Store id represents the unique identifier for each restaurant (0-7 for a total of eight restaurants). Day num represents the day number collected relative to the beginning of the experiment/rollout. Has mobile is a boolean representing if/when a restaurant receives the mobile thru. Percent revenue member represents the proportion of revenue at the restaurant for the day generated from members (i.e. via the app).
To help with visualizations, we create a new column called gets_treat to show which restaurants will receive treatment. In our study, this corresponds to restaurants 0, 2, 4, and 6. Each of these restaurants, as stated earlier in the post, has a similar restaurant within the same region that acts as the control (Note: in our analysis, we assume homogeneity across geographic regions). Thus, one interesting visualization would be plotting the 100-day experiment comparing the response variable between treated restaurants and controls. This is shown in Figure 4.1.
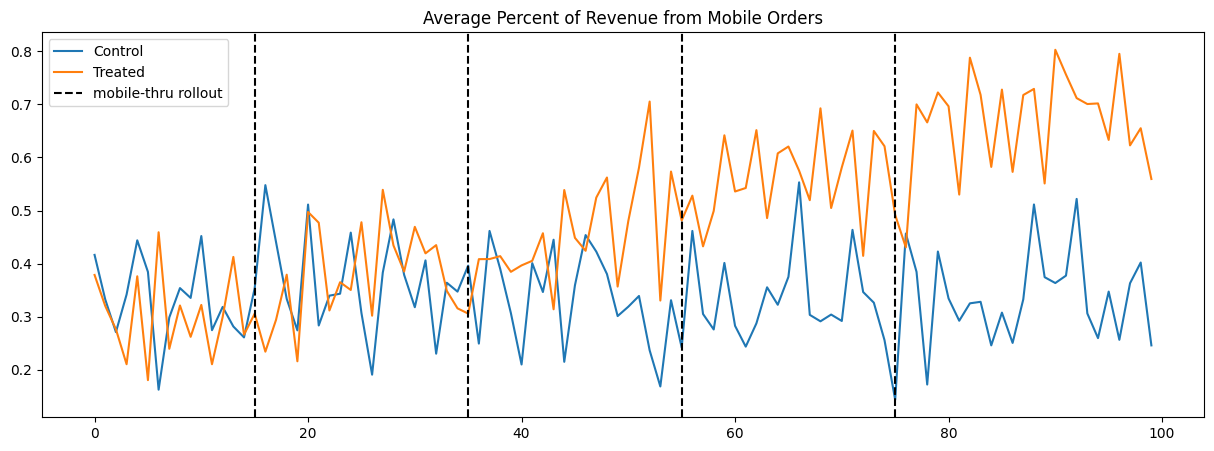
The dotted black lines in Figure 4.1 show the rollout dates for each of the restaurants in the study. As we approach the 100-day mark, the distance between the treated and control restaurants grows larger, indicating a potential treatment effect. To verify if this is true across all restaurants or if one restaurant is driving this change, we plot each region separately in Figure 4.2.
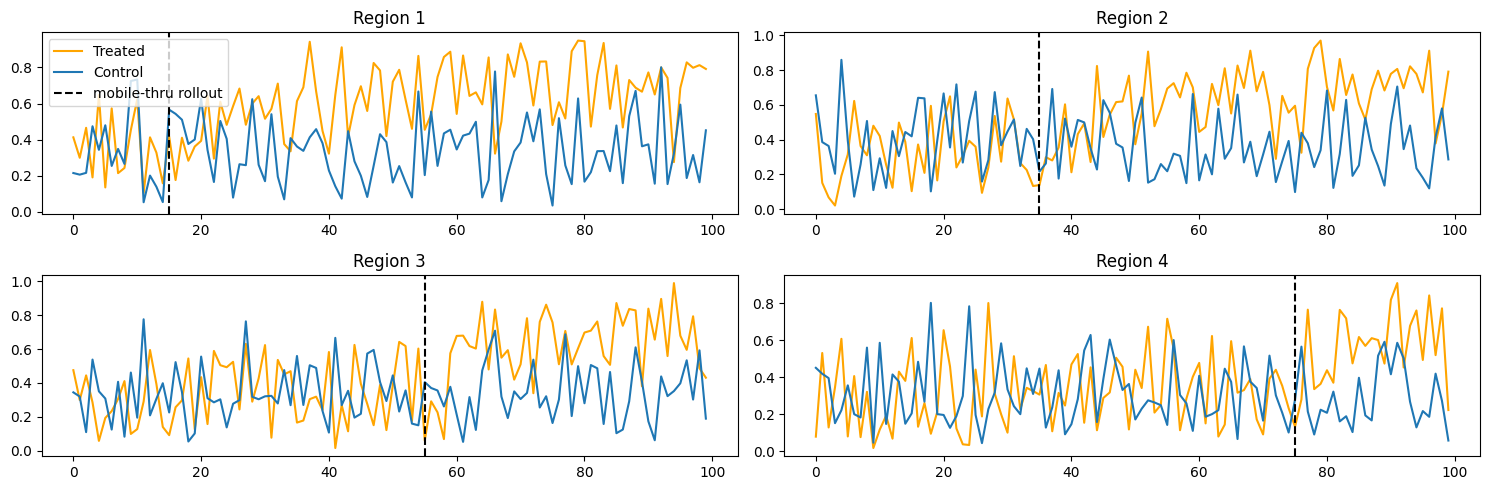
The graph above verifies that each region tested shows a growing gap between treated and control restaurants. As such, we’d like to quantify this gap to help Chick-fil-A know on average what a full mobile-thru rollout would do for driving an increase in mobile-app order usage.
Calculating Causal Effect via Synthetic Difference-in-Difference (SDiD)
Since we are dealing with panel data, a hard date for treatment implementation, and no treatment rollback, a common approach to this would be using a Difference-in-Differences [8] estimator. However, recent studies have shown that in the case of potential heterogeneous treatment effects and staggered rollouts, this estimator can become biased [9].
To handle such broken assumptions, one can use Synthetic Control Method (SCM) [10]. However, this approach lacks the ability to account for multiple treated units and staggered rollout dates. While we could perform four separate SCMs to generate causal inference, this method would fail to pool information acrosss all units to get a stable average treatment effect of the treated (ATT). Therefore, we need a framework that allows us to utilize all the information across our four regions that doesn’t break when with staggered rollouts.
In 2021, Dmitry Arkhangelsky, Susan Athey, David A. Hirshberg, Guido W. Imbens, and Stefan Wager published Synthetic Difference-in-Differences (SDiD [11]. This estimator combines the best of both worlds of DiD and SCM. For our purposes, it can handle multiple treated and control units, allows for staggered rollouts, and has a more robust counterfactual estimate since it uses weights from DiD and SCM.
SDiD Model and Results
Notice: We’d like to recognize the work of [11] and the work of Matheus Facure [Facure:SynDiD]. We use Matheus’s implementation of SDiD in our post and highly recommend that people read his book, Causal Inference for The Brave and True.
In most causal inference models, we are dealing with estimating what is happening versus what could have happened using the potential outcomes framework [12]. To do this in our analysis, we begin by deriving the SDiD estimator by showing the optimization equations for DiD and SCM in Equation 5.1.
\hat{\tau}^{sc} = \underset{\beta, \tau}{argmin} \bigg\{ \sum_{i=1}^N \sum_{t=1}^T \big(Y_{it} - \beta_t - \tau D_{it}\big)^2 \hat{w}^{sc}_i \bigg\} \hat{\tau}^{did} = \underset{\mu, \alpha, \beta, \tau}{argmin} \bigg\{ \sum_{i=1}^N \sum_{t=1}^T \big(Y_{it} - (\mu + \alpha_i + \beta_t + \tau D_{it}\big)^2 \bigg\} \tag{5.1}
The top equation is for SCM. In SCM, we attempt to find the parameters \beta and \tau that minimize the difference between the observed result Y_{it}. In DiD, we attempt to find parameters \mu, \alpha, \beta, and \tau that minize the difference between the observed result Y_{it}. The goal in SCM is to generate a counterfactual that mimics the pre-treatment period for the treated unit. Likewise, in DiD, we use a control unit that mimics the behavior of the treated unit (i.e. follows the parallel trends assumption).
In SDiD, we merge the two equations together to get Equation 5.2. We describe each part of this equation in the list below.
\hat{\tau}^{sdid} = \underset{\mu, \alpha, \beta, \tau}{argmin} \bigg\{ \sum_{i=1}^N \sum_{t=1}^T \big(Y_{it} - (\mu + \alpha_i + \beta_t + \tau D_{it})^2 \hat{w}^{sdid}_i \hat{\lambda}^{sdid}_t \big) \bigg\} \tag{5.2}
\begin{split} \hat{\lambda}^{sdid} = \underset{\lambda}{\mathrm{argmin}} \ ||\bar{\pmb{y}}_{post, co} - (\pmb{\lambda}_{pre} \pmb{Y}_{pre, co} + \lambda_0)||^2_2 \\ \text{s.t } \ \sum \lambda_t = 1 \text{ and } \ \lambda_t > 0 \ \forall \ t \end{split} \tag{5.3}
\begin{split} \hat{w}^{sdid} = \underset{w}{\mathrm{argmin}} \ ||\bar{\pmb{y}}_{pre, tr} - (\pmb{Y}_{pre, co} \pmb{w}_{co} + w_0)||^2_2 + \zeta^2 T_{pre} ||\pmb{w}_{co}||^2_2\\ \text{s.t } \ \sum w_i = 1 \text{ and } \ w_i > 0 \ \forall \ i \end{split} \tag{5.4}
- Y_{it} is the actual outcome for restaurant i at time t
- \mu is the baseline of the counterfactual
- \alpha_{i} is the fixed effect for the ith restaurant
- \beta_{t} is the time fixed effect for time t
- D_{it} is the treatment indicator (1 for treated, 0 for control)
- \tau is the ATT
- \hat{w_{i}}^{sdid} is the ith unit weight from SCM
- \hat{\lambda_{t}}^{sdid} is the th time weight
We won’t go into too much detail with Equation 5.3 nor Equation 5.4, as they are mostly there for reference as to where those weights come from. The critical equation is Equation 5.2, which shows that it is a balanced combination of SCM and DiD. This means that SDiD finds optimal parameters that both estimate the treated unit’s counterfactual trajectory. In short, the SDiD estimator becomes a doubly robust estimator for estimating ATT.
In particular, SDiD is a doubly robust estimator in staggered adoption designs. Because SDiD relies on block-matrix design (see [11] section 8 for more information), we adjust this block design by running SDiD four times across the four treated units while still comparing them across all the controls. After fitting our data to the SDiD estimator, we obtain the ATT shown below.
ATT: 0.3035668498514986Our ATT indicates that restaurants that have implemented the mobile-thru have, on average, about a 0.31 increase in the proportion of revenue generated from mobile orders. This is a major increase! Previously, drive-thrus had, on average, about 30% of revenue from mobile orders. Now, with mobile-thrus, this number is basically double.
Note: In a more thorough analysis (and obviously with real data), we’d want to verify this ATT by performing other statistical tests and reporting relevant statistical measures. However, since this is synthetic data for a synthetic example, it suffices to show that the SDiD correctly uncovered the underlying causal mechanism, accounting for confounding effects and properly handling the staggered rollout.
From Causal Modeling to Business Strategy
At the end of the day, causal modeling is merely a tool to inform business strategy. Knowing that mobile-thrus in our small experiment increased the proportion of mobile orders is great, but what should we do with this information? What are the available resources and capabilities of Chick-fil-A to maximize this opportunity?
As mentioned earlier in the post, Chick-fil-A has been increasingly focused on improving the drive-thru to make it the go-to spot for speed and accuracy. Furthermore, Chick-fil-A has been investing a lot into their digital touchpoints with customers via their mobile application. With these two main focuses and the result of the mobile-thru experiment, Chick-fil-A is well positioned to merge these two worlds to maximize its value chain [13].
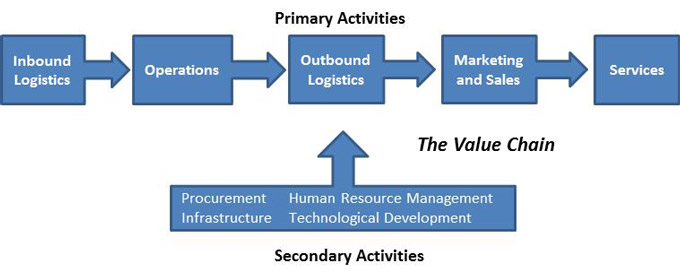
The value chain consists of the intentional steps a business takes to provide a good or service to its customers. In our case, Chick-fil-A is aiming to provide food to its customers in a friendly and efficient way, particularly through the drive-thru.
The combination of the mobile app with the mobile-thru provides a new way for Chick-fil-A to operationalize their business. These changes can be summarized in two areas below.
Operational Efficiency
The increase in mobile orders means increased insight into customer purchase patterns. We can now know the minute of the day, distance, and preference of food for each individual customer. Since we have a more accurate picture into what customers are looking to purchase, we can leverage predictive analytics to more accurately forecast our supply chain needs and workforce management.
Furthermore, since we have continuous feedback from customers, these models can be continuously updated to match the current trends and preferences of customers. By planning our resources around this new reliable source of data, Chick-fil-A can enhance operational efficiency to drive profits.
Personalized Customer Experience
The app gives incredible insight into each customer’s tastes and preferences. As more users continue to go into the app, we can get better insights into different customer demographics and activities. Using those insights, we can better personalize deals and opportunities. We can understand the timing of sending promotions, different app layouts to maximize customer checkout throughput, etc. There are a plethora of ways Chick-fil-A can leverage this new digital touchpoint to better position themselves to provide maximum value to their customers.
Conclusion
In this post, we reviewed the rich history of Chick-fil-A, its current drive-thru strategy, and a potential new avenue with mobile-thrus. We used queue theory to analyze the current system and the potential changes in drive-thru efficiency by implementing a mobile-thru. We then designed an experiment to test this mobile-thru and used the SDiD estimator to extract a causal effect. After calculating this causal effect, we used it to guide our business strategy to improve two areas of our business: operational efficiency and customer experience personalization.
Overall, we hope this post illustrated the importance of combining causal models with business strategy. Causality is most useful when implemented in a framework of business strategy, and business strategy is most robust when tested via rigorous and robust models. The combination of both can provide great results for any business.
References
[1]
J. Agate, “The incredible history of the drive-thru,” Lovefood, Jun. 2024, Accessed: Aug. 06, 2025. [Online]. Available: https://www.lovefood.com/gallerylist/98185/the-incredible-history-of-the-drive-thru
[2]
A. Goyal, “Drive-thru restaurant statistics: Trends, performance data & consumer insights,” Restroworks, Jun. 2025, Accessed: Aug. 06, 2025. [Online]. Available: https://www.restroworks.com/blog/drive-thru-restaurant-statistics/
[3]
Georgia Historical Society, “Chick-fil-a.” May 2020. Accessed: Aug. 06, 2025. [Online]. Available: https://georgiahistory.com/wp-content/uploads/2020/05/Chick-fil-A.pdf
[4]
A. K. Erlang, “Solution of some problems in the theory of probabilities of significance in automatic telephone exchanges,” Elektrotkeknikeren, vol. 13, pp. 5–13, 1917.
[5]
D. G. Kendall, “Stochastic processes occurring in the theory of queues and their analysis by the method of the imbedded markov chain,” The Annals of Mathematical Statistics, vol. 24, no. 3, pp. 338–354, 1953, doi: 10.1214/aoms/1177728975.
[6]
R. H. Thaler and C. R. Sunstein, Nudge: Improving decisions about health, wealth, and happiness. New Haven, CT: Yale University Press, 2008.
[8]
D. Card and A. B. Krueger, “Minimum wages and employment: A case study of the fast-food industry in new jersey and pennsylvania,” The American Economic Review, vol. 84, no. 4, pp. 772–793, 1994.
[9]
A. Goodman-Bacon, “Difference-in-differences with variation in treatment timing,” Journal of Econometrics, vol. 225, no. 2, pp. 254–277, 2021, doi: 10.1016/j.jeconom.2021.01.002.
[10]
A. Abadie, A. Diamond, and J. Hainmueller, “Synthetic control methods for comparative case studies: Estimating the effect of california’s tobacco control program,” Journal of the American Statistical Association, vol. 105, no. 490, pp. 493–505, 2010, doi: 10.1198/jasa.2009.ap08746.
[11]
D. Arkhangelsky, S. Athey, D. A. Hirshberg, G. W. Imbens, and S. Wager, “Synthetic difference-in-differences,” American Economic Review, vol. 111, no. 12, pp. 4088–4118, 2021, doi: 10.1257/aer.20190159.
[12]
D. B. Rubin, “Estimating causal effects of treatments in randomized and nonrandomized studies,” Journal of Educational Psychology, vol. 66, no. 5, pp. 688–701, 1974.
[13]
M. E. Porter, Competitive advantage: Creating and sustaining superior performance. New York, NY: Free Press, 1985.