Abstract
In this post, we present a prototype recommendation system based on Deep Neural Networks for YouTube Recommendations [1] and Explore, Exploit, Explain: Personalizing Explainable Recommendations with Bandits [2]. We present the prototype in the context of a company that operates as a short-video content platform. We define the strategy behind the prototype by presenting the business objectives. We follow this by walking through the architecture of the prototype and how it fulfills the objectives of the company. We end by illustrating potential next steps for our company. The code for this prototype can be found at the github repo.
Introduction
InstaTok is a new social media app that specializes in short-video content. The platform operates as a two-sided marketplace. There are user accounts and creator accounts. Anyone can sign-up for a user account for free. To join as a creator, creators must pay a small subscription fee plus a small commission, both billed monthly.
Users interact with content via a mobile application. Like other short-video platforms, users are presented a for-you-page (FYP) with a single video playing. Users can choose to watch the video as many times as they like or move onto the next video at any time by swipping up on the app.
Creators are incentivized to be on the platform by monetizing their videos through advertisements. InstaTok has partnerships with various brands to connect them with creators to advertise their products and services. Creators are then compensated directly by these companies based on their contractual agreements.
Since InstaTok is a two-sided platform, we need to optimize experiences for both users and creators. Users need good videos to stay engaged and creators need users to monetize their videos. In order to balance these needs, we can define sound strategy on how we can define the problem and how it can be solved with it.
Note: While this would technically be a three-sided marketplace since brands also would need to benefit from the platform, we are simplifying this problem to a two-sided one for this post.
Company Strategy
As mentioned previously, in order for InstaTok to succeed, we need to develop a product that is appealing to both users and creators. In order to create a sound product that answers to both user and creator needs, we need to develop a robust strategy that will guide our approach to product creation. To do this, we need to answer four questions.
- Where do we compete?
- What unique value do we bring to the market?
- What resources and capabilities can we utilize to deliver unique value?
- How do we sustain our ability to provide unique value?
We have established that we are competing in the mobile application market, specifically within the short-video platform arena. We hope to appeal to all ages, but are aiming to capture the college-young professional market. Furthermore, we are looking for those who are looking to separate the world of social media and creative short-video content.
We need to provide unique value to both sides of our market. For our users, we are providing a platform where all content is created by official creators. There are no random company ads appearing in the FYP nor social connection content. We focus the user experience on entertainment content. On top of that, we provide personalization to our users by algorithmically matching them with content they would enjoy.
For our creators, we provide unique value through monetization and verified creator status. Creators compete solely with other creators for views, not with general social media users. Additionally, other platforms collect the ad revenue generated by creator content. On our platform, we provide a way for creators to directly collect ad revenue from brands.
Our key resource and capabilities include our proprietary algorithms, our brand partnerships, and deep technology expertise. These are also key in how we sustain our unique value. By continuing to iterate our algorithms, grow our partnerships, and deepen our technology expertise, we can sustain a unique advantage in this marketplace.
From Strategy to Product
We’ve defined our company strategy, and now we must use it to create a viable product. Our minimum viable product (MVP) should be a mobile application with a user-friendly interface. This interface should provide short-video content to our users one video at a time. Users advance to the next video by swiping up on the screen. These functions should be designed in a way that is intuitive for our target demographic. Additionally, the algorithms powering the service need to be personalized to maximize each user’s specific utility.
In this post, we will focus our attention on the personalization algorithms powering our platform. As mentioned, our personalization algorithm is one of our key resources/capabilities in our company strategy. We need it to be incredibly valuable in the eyes of our users and creators. To achieve this, we utilize data to drive our decision making. Table 2.1 shows an example of this kind of data.
| Region | Interest |
|---|---|
| west | tech |
| mid | animals |
| east | food |
According to our market research, users generally have two categories of videos that entice them to keep watching. Furthermore, we learned that users are open to exploring new categories of videos based on their geographic location. For example, those in the midwest appear to be open to exploring videos featuring animals. These insights should drive product development for our personalization algorithm.
Personalization Algorithm
System Design
While previous sections have focused on the business aspects of our product, this section describes the technical details needed to design and implement a personalization system. Our problem can be boiled down to this one question: how can we optimize our content offerings for any given user such that a creator maximizes their revenue? To do this, we begin with simple microeconomic theory. We believe that any given user is a rational agent seeking to maximize their utility. We further believe that users have downloaded InstaTok to maiximize their entertainment utility. Therefore, if we provide them with videos that help maximize this utility, they will continue to use the platform (i.e. maximize their watch time per session).
To answer our question on how we can maximize entertainment utility for a given user, we propose a system in Figure 3.1 that illustrates how we can capture user data to provide meaningful personalization.
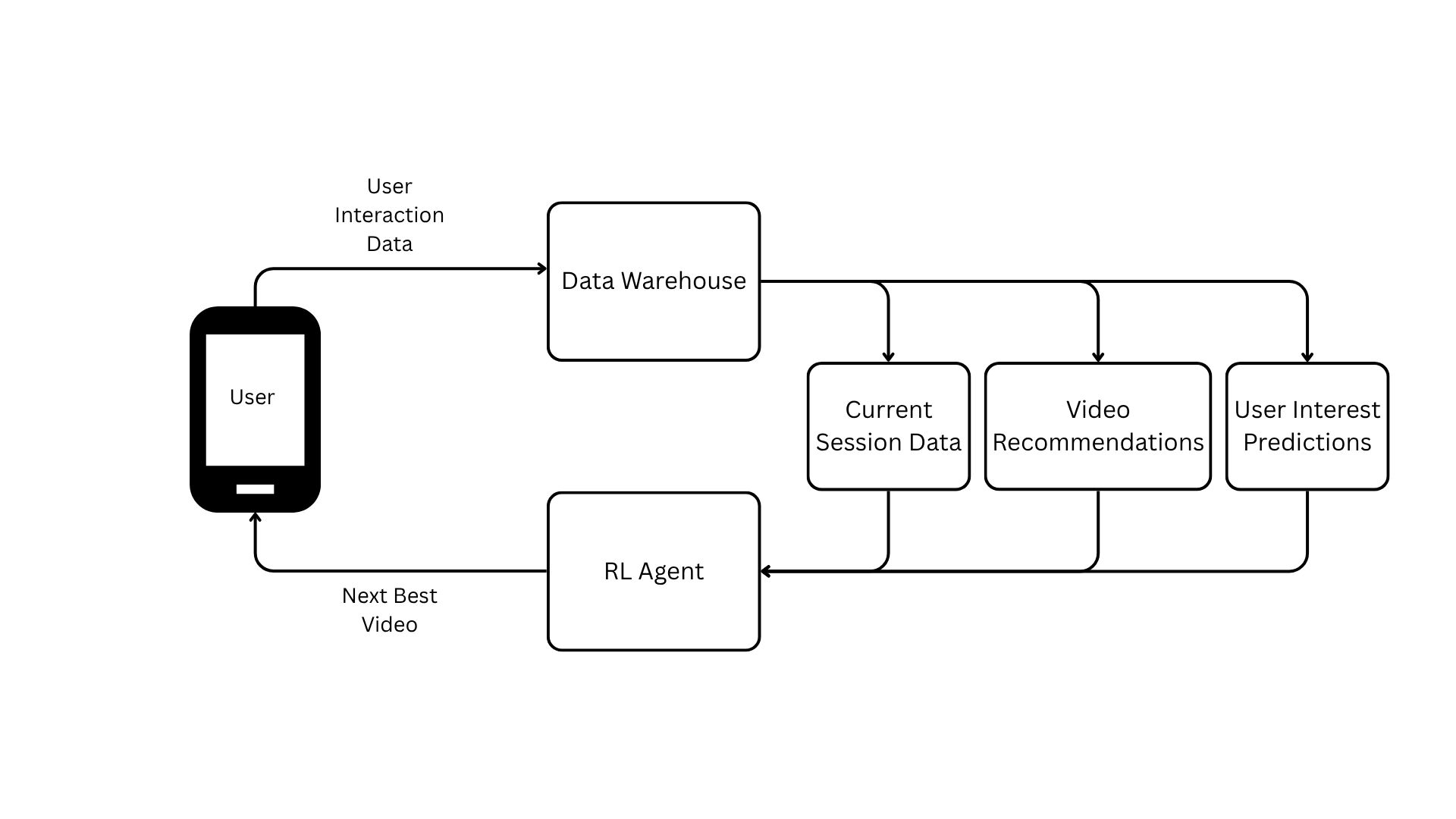
Figure 3.1 begins with a user opening our app and interacting with a shown video. The interaction data is sent to our data warehouse where it is stored with historical interaction data. Data is then sent from the warehouse to three functions. These functions help define the current state of our user. The first function retrieves current session data pertinent to our given user (e.g. demographic data, location data, etc.).
The second function is our base recommendation system. The system parses our large video catalog and generates a candidate list of videos that best match user preferences. This list is further refined by adjusting the scores from the base recommendation with additional business logic. We will discuss the base recommendation algorithm in detail later on.
The third function is our interest prediction layer. To better inform our decision on which video to show the user, we use past interaction data to predict user interest categories. Note: In a true production environment, this would be our approach. However, for the purposes of this post, we randomly generate these interests for each user.
These functions provide output that defines the current state of the user. This state is fed into our reinforcement learning agent (RL agent) which then chooses which action to take (i.e. which video to show the user next). The selection is sent back to the user and the process repeats itself until the user closes the app. We will provide more detail on the RL agent later on.
Recommendation System Architecture
Our recommendation system is a simple two-phase architecture. The first phase is the initial candidate list generation. To do this, we first assign scores to the interaction data. Table 3.1 shows our assignment scores.
| Interaction | Score |
|---|---|
| watched | 1 |
| skipped | -2 |
| liked | 2 |
| other | -0.5 |
These scores are aggregated to create a item-user matrix, as depicted in Equation 3.1. Note: For faster computation, we transform this into a sparse matrix using scipy.
\begin{pmatrix} 2 & -.5 & 1 \\ 1 & 1 & 1 \\ 2 & -2 & 1 \end{pmatrix} \tag{3.1}
Equation 3.1 is a n by m matrix where each row i is an item and each column j is a user. The goal of setting the matrix like this is to identify relationships between items. We want to identify which items are most similar to each other based on similar scores from users. To calculate this, we utilize cosine similarity [3] as shown in Equation 3.2.
\text{similarity}(A, B) = \frac{A \cdot B}{\|A\| \|B\|} \tag{3.2}
Equation 3.2 allows us to measure the cosine of the angle between two item vectors. A smaller angle means higher similarity. Once these are all calculated, the results are stored in a n by n matrix, where each row and column corresponds to a specific item (i.e. an item-item matrix). We can then perform lookups on this matrix to recommend items that are most similar to those a user previously interacted positively with. Once we have r number of recommendations for a user, these items with their respective scores are sent to our weighted-sum function for weighting based on important business objectives. This process of using item-item similarity and weighting according to business objectives is known as collaborative filtering [4].
\text{Final Score} = w_{1}\text{Similarity Score} + w_{2}\text{Num Views} + w_{3}\text{Is Interest} \tag{3.3}
The final score of a video is weighted by three key attributes: the similarity score (produced from Equation 3.1), the number of views a video has (the popularity of it), and a boolean variable indicating whether the video aligns with the user’s interests.
RL Agent Architecture
Our recommendation system currently outputs the top r recommendations for a user based on their past interaction history. This is a great feature, but it does not capture the entire story of a user. Each time a user opens our app, they are in a different state of being. They could be bored, anxious, excited, or experiencing any other emotion. To better understand our users and present them content that aligns with their current state, we utilize reinforcement learning (RL) to model these states and their subsequent feedback. RL is the industry standard for capturing sequential decision making.
From a high-level, we refer back to Figure 3.1. The RL agent takes in current session information (number of videos watched so far, number of skips, last video category show, etc), the candidate list of videos with their final scores, and current “predicted” user interests. The RL agent then chooses an action (i.e. which video to show), sends that video to the user, and records the interaction. As the RL agent continues to do this, it learns which states matches certain videos. The more data it has around the interactions between users and videos given current states, the more optimized its policy will be at choosing the correct next best video.
To model this system, we use a Deep Q Network (DQN) [5]. The DQN utilizes neural networks to approximate the Q Function [6], as shown in Equation 3.4.
Q^*(s, a) = \mathbb{E}_{s' \sim P(\cdot|s,a)} \left[ r + \gamma \max_{a'} Q^*(s', a') \right] \tag{3.4}
Equation 3.4 is the optimal Q-value function for a Q-learning algorithm. The equation basically says that the optimal Q-value for taking action a in state s is equal the expectation of the sum of the immediate reward of taking action a in state s and the optimal Q-value for the next state s over all possible next actions a. Simply put, this function estimates the expected future cumulative reward of taking action a in state s.
In our DQN, we estimate these Q-values using neural networks. The neural network takes the current state s as input, passes it through the hidden layers, and produces r number of Q-values. The DQN then chooses a video to show the user. To do this, we use an epsilon-greedy [7] approach to balance exploration with exploitation. The video is then shown to the user, the user interacts with the video, the interaction is recorded, and the process begins again.
Our DQN learns via experience replay. The RL agent learns via mini-batches of experiences that are randomly sampled from a “memory storage”. This breaks correlation and improves training stability. The training is performed like many other DL algorithms where we attempt to minimize a loss function. In our prototype, we use mean squared error. The loss is calculated as the difference between our target Q-value and the predicted Q-value, as shown in Equation 3.5.
\min_{\theta} \mathcal{L}(\theta) = \min_{\theta} \mathbb{E} \left[ \left( Y - Q(s, a; \theta) \right)^2 \right] \tag{3.5}
Since we don’t directly observe target Q-values in the real world, we estimate them via a target network in our RL agent. Our predicted Q-values are derived from an entirely different network known as the online network.
All specific technical details of the DQN, state and action space, etc. can be found at the github link in the abstract.
Conclusion
In this post, we presented InstaTok, a short-video platform aimed at revolutionizing the short-video entertainment space by providing ad-free experiences to users via a new incentive and verification structure for creators. We walked through the core company strategy and product development on how we can create a prodcut to fulfill the needs of both users and creators. We presented a high-level overview of a user’s journey on the app, as well as deeper technical details of how we can algorithmically match users to videos they would enjoy, thereby maximizing their watch time per session. In a real-life scenario where we’d be launching this system, we’d want to implement experiments to properly measure changes in user watch time between different algorithms (e.g. testing a different base recommendation system vs current one to observe its impact on user watch time).
Overall, we hope this post demonstrated the power of recommendation systems and the importance of each layer of the system. Additionally, we hope that readers gained an appreciation for how sound business strategy can guide product development. With both good business strategy and deep technical expertise, one can build an app like TikTok following the principles outlined in this post.
For code of this prototype, see github repo.