Abstract
In this post, we present the situation of a grocery store chain looking to decrease checkout-time by supplying scanner guns at self-checkout registers. We demonstrate first the usefulness of difference-in-differences (DiD) methodology in calculating causal effects of the intervention. We then demonstrate how to utilize synthetic control methods (SCM) to perform DiD when there is not a single suitable control unit available. The code for this analysis can be found in the github repo.
Introduction
My-Warehouse (MW) is a regional warehouse club that has gained popularity along the west coast of the USA. MW has gained popularity for its bulk supply of local produce, meat, and other local specialty items from small businesses that can be bought at bulk for at a slight discount compared to other retailers. MW currently operates out of 11 stores in 11 distinct cities along the west coast.
After analyzing customer data regarding how to improve the shopping experience in their stores, one clear suggestion came through: decrease time to checkout. With the growing popularity of MW, many new customers are anxious to get into the store and try local items. However, they become frustrated with how long they have to wait to checkout. Even with the addition of self-checkout, customers still wait too long in lines during peak hours.
One suggestion to decrease checkout time is to provide scanner guns at each self-checkout register, allowing customers to scan the items in their cart instead of unloading each item. A pilot program was recently launched in the Seattle store (SEA). We are tasked with analyzing the data from this program and recommending if the program should be launched across all stores.
Establishing the Operations
Understanding Optimal Efficiency with Cycle Time and Throughput Rate
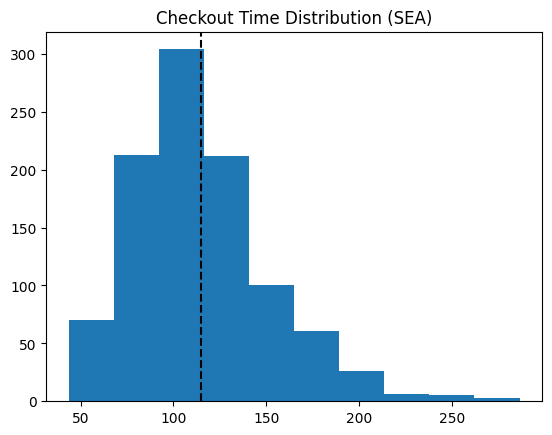
To begin our analysis, we establish the current flow of traffic in the store, specifically at checkouts. To do this, we’ll look at the current checkout time distribution at SEA, shown in Figure 3.1.
From Figure 3.1, we expect a customer at the SEA store to take about 120 seconds on average to complete the checkout process. We’ll assume the process of checkout to be as follows.
- Customer scans membership card (begins timer).
- Customer begins scanning each individual item and places item on side platform next to register.
- After scanning all items, customer pays for items (only accepts cards at self-checkouts).
- Customer returns all items to cart and transaction ends.
The time to move one unit (ie one customer) through the above process is known as cycle time (CT). In MW stores, there are 4 self-checkout registers available for customers to use. In the optimal scenario, each station would begin and end in parallel and the demand for each station would immediately be filled. The total output from these 4 stations over a specified time interval is defined as throughput rate (TPR). The relations between CT and TPR are shown in Equation 3.1.
CT = \text{average time to process one unit} TPR = \frac{\text{num units produced}}{\text{total time elapsed}} TPR = \frac{1}{CT} \tag{3.1}
From Equation 3.1, TPR is the reciprocal of CT. Since we have CT, we know TPR must equal 1 / 120 seconds. To gain a more practical view of the operations, we’ll convert this to minutes and say that our TPR is 1 / 2 minutes, or half a customer per minute is our TPR. Additionally, since we have 4 stations, we multiply this TPR by 4 to get 2 customers per minute on average. This is the assumed peak efficiency of our current system.
Queue Theory
In the previous section, we established the peak efficiency the system can handle through CT and TPR. One of the big assumptions we placed on this system was a steady-state flow, meaning there would be immediate demand for each station once they became free. In the real-world, steady state is nearly impossible to achieve. Additionally (and possibly more importantly for us), understanding the current wait time of customers will help us to identify how speeding up the above system can help decrease wait time. This branch of operations is known as queue theory.
While we will not provide an exhaustive tutorial on queue theory in this post, we will provide the necessary overview for this section. To do this, we begin with Kendall’s Notation[1]. Kendall’s notation provides a framework where we identify the 3 core components of queue creation, shown in Equation 3.2.
A: \text{arrival process distribution (how often customers arrive)} B: \text{service time distribution (how long it takes to serve a customer)} C: \text{number of servers} \tag{3.2}
From the previous section, we learned B (defined as our CT) and C (4 self-checkout stations). We must now identify A. Let \lambda denote the average arrival rate of customers. In the context of our problem, we will suppose \lambda to be the average arrival rate during our peak hours (since slow hours do not tend to have any kind of queue). The arrival distribution (which we model as a poisson distribution) is shown below in Figure 3.2.
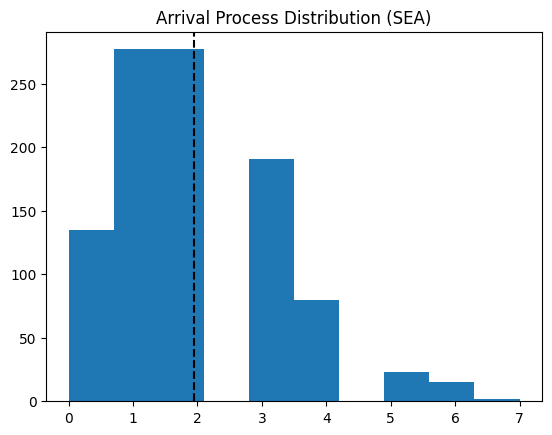
On average (during peak hours), we have about 2 customers arriving per minute. To better know the amount of time our registers are busy, we calculate system utilization, commonly denoted by \rho. The formula for \rho is found in Equation 3.3.
\rho = \frac{\lambda}{c\mu} \tag{3.3}
System utilization is the defined as the ratio between the average arrival rate and the TPR we previously calculted. In our case, \rho comes out to be .95, or 95%. According to queue theory, a system is stable if \rho is < 1. Our current system is therefore stable and allows us to use M/M/c formulas to calculate relevant wait time and queue length metrics. The formulas used all depend on Little’s Law[2], illustrated in Equation 3.4.
L = \lambda W \tag{3.4}
L represents the number of customers in the queue, \lambda is the arrival rate of the customers, and W is the wait time of the customers. For our system specifically, we use an adapted version of Equation 3.4, as shown in Equation 3.5.
L_{q} = \frac{P_w \rho}{1-\rho} \tag{3.5}
Equation 3.5 utilizes Erlang’s formula[3] to get P_w, which is the probability of an arriving customer having to wait in the queue. This is scaled by result of \frac{\rho}{1-\rho}. The result gives us the average length of the queue at any point in time (during peak hours). While we won’t cover the full derivation and calculation of P_w, we provide that the value of it is approximately .9. Plugging this value in with our \rho value, we get L_q is equal to about 16.93, or about 17 people on average are waiting in the queue during peak shopping hours. That’s a lot of people!
To calculate the average time a customer waits in the queue, we utilize Equation 3.4 by rearranging the equation to solve for W. After performing some calculations, we get W is equal to 8.91 minutes. MW customers on average wait almost 9 minutes in line during peak shopping hours!
Establishing Causality
In the previous section, we laid out the current system design of MW stores, specifically for the checkout experience. We identified through our current models that customers experience long lines (on average 17 customers in queue) and consequently long wait times (about 9 minutes waiting in queue). To address this issue in the system, MW launched a pilot program in the Seattle store to see if giving customers scanner guns at self-checkout would decrease queue wait time. Essentially, if we can decrease CT, we can increase TPR and thus move people through the queue more quickly.
What MW is attempting to gain is causal inference from their intervention. MW hopes to know that if they implement this program across all their stores, then their chcekout times will decrease. The gold standard when it comes to establishing cause-effect relationships is performing a randomized controlled trial (RCT). This is also known as A/B testing in some scenarios. In our scenario, we could randomly assign some stores to be control (i.e. no change in the system) and other stores to the treatment (the scanner guns). We then measure their difference in outcomes and attribute any difference in outcome to the treatment effect, assuming that the RCT was designed properly and followed the core assumptions of causal inference.
While in theory this is the easiest route, in practice it is not always the best approach. For MW, this would mean having to buy scanner guns for n number of stores that needed the treatment, without knowing if they would be going ahead with the program or not. Furthermore, training staff at each treatment location on how to implement scanner guns would also generate more costs. Identifying causal inference in business needs to be balanced with the expected costs of experiments.
Experiment Design 1: Difference-in-Differences
One approach we can take to help MW is to assign just one store the treatment and compare it with another store that is fairly comparable to the treated store. This approach is know as the Difference-in-Differences (DiD)[4] model. DiD is known as a quasi-experimental design since it doesn’t rely on random assignment. Instead, it “mimics” the effects of RCTs by accounting for unobserved confounders by measuring the change in outcomes to a similar unit. Specifically, this is known as the parallel trends assumption. DiD assumes that both the treated unit and the control unit follow parallel trends had there not been any intervention. Mathematically, this is represented as a linear model as shown in Equation 4.1.
Y_{i} = \beta_{0} + \beta_{1}SEA_{i} + \beta_{2}POST_{i} + \beta_{3}(SEA_{i}*POST_{i}) + \epsilon_{i} \tag{4.1}
Y_{i} is the outcome being measured (average checkout time), SEA_{i} is a dummy variable indicating whether the observation is in Seattle or not. POST_{i} is a dummy variable indicating whether or not the observation occurred after the intervention. We then have the interaction term where \beta_{3} would show the average treatment effect between Seattle and the control city after the intervention was applied.
To get a little more granular into how a simple OLS regression model derives causal effects from this design, consider the basic case of the potential outcomes framework[5]. We extend this to DiD by saying each observation takes on an outcome of Y_{D}(T), where D is the treatment assignment (1 for Seattle and 0 for the control) and T is the time period (1 for post intervention and 0 for pre intervention). In the counterfactual world, we would be able to calculate the average treatment effect of treated (ATT) by computing E[Y_{1}(1) - Y_{0}(1)|D=1]. However, Y_{0}(1) is the counterfactual for any given observation where we observe the treated in post intervention. To work around this, we replace the missing counterfactual by setting it equal to E[Y_{0}(0)|D=1] + (E[Y_{0}(1)|D=0] - E[Y_{0}(0)|D=0]). With a bit of rearranging to the original “preferred” equation, we arrive at Equation 4.2.
ATT = (E[Y(1)| D=1] - E[Y(0)| D=1]) - (E[Y(1)| D=0] - E[Y(0)| D=0]) \tag{4.2}
In essence, we take the difference between the treatment post and pre intervention and the difference between the control post and pre intervention, then take the difference of those differences. Hence, we arrive at the name “difference-in-differences”.
DiD Results
Since we’ve now established how we can model our problem using DiD, we can now get into the results of our model. As stated previously, Seattle is the location our treatment (i.e. implementing scanner guns for check-outs). From previous analysis, we believe a good control candidate that follows our DiD assumptions would be San Francisco (SF). We collected data over 100 days from both locations. At the 50 day mark, we rolled out the scanner guns in Seattle. Figure 4.1 shows the data we collected over time at both SEA and SF.
| avg_ct | sea | post_int | |
|---|---|---|---|
| 0 | 115.429541 | 1 | False |
| 1 | 130.756135 | 0 | False |
| 2 | 113.958007 | 1 | False |
| 3 | 122.035513 | 0 | False |
| 4 | 114.782158 | 1 | False |
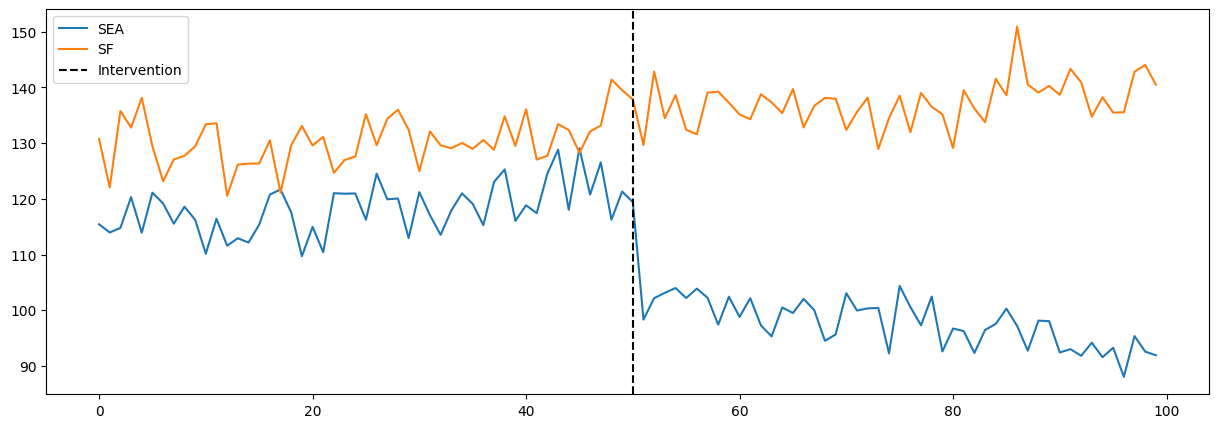
From Figure 4.1, we see that SEA and SF follow similar trends up till time of intervention. When the scanner guns are implemented, there is a sharp decrease in average check-out time with a continual downward trend. This is a great indication that our program provided significant decrease to CT. To get a numerical value from this graph, we can extract it manually by performing the above calculations using the data or by fitting a OLS model (they both provide the same result. Below we provide both results.
True DiD Estimate: -27.421232456603718| coef | std err | t | P>|t| | [0.025 | 0.975] | |
| Intercept | 130.4273 | 0.607 | 214.823 | 0.000 | 129.230 | 131.625 |
| post_int[T.True] | 6.8350 | 0.867 | 7.880 | 0.000 | 5.125 | 8.546 |
| sea | -12.1969 | 0.859 | -14.205 | 0.000 | -13.890 | -10.504 |
| sea:post_int[T.True] | -27.4212 | 1.227 | -22.355 | 0.000 | -29.840 | -25.002 |
The added value we gain from fitting the OLS is that we gain SE estimates and subsequent CI estimates. According to our model, scanner guns provide an on average decrease of about 27 seconds. Recalling what we calculated in the operations section, our new CT would be approximately 93 seconds. This means our new TPR would be approximately 2.58 customers per minute (a 29% increase in TPR). This results in a change in system utilization from 95% to about 74%. From here, we calculate our average queue length to be 1.36 customers (a 92% decrease in average queue length!) which then results in average wait time in the queue to be about 43 seconds (or .715 minutes, also a 92% decrease!).
According to our models, the scanner guns are a huge success and represent a major opportunity for MW to increase customer satisfaction through higher operational efficiency. While we did derive useful causal effects from this experiment, MW should obviously consider other factors like feasability of company wide adoption, cost and maintenance of the equipment, and potential other factors like increases in theft from not scanning all items.
Experimental Design 2: Synthetic Control
As explained in the DiD section, one of the key assumtions behind the DiD model is the parallel trends assumption. In order for our model to be valid, we need to find an adequate enough control unit that follows a close enough parallel trend, along with the other usual assumptions of causality. This assumption is regularly broken in the real world as it is difficult to find a control unit that satisfies the model assumptions.
Instead of attempting to find a single control unit to compare our control to, we can “create” our own control by using synthetic control methods[6]. We create a synthetic control by taking a weighted average of all our possible controls (i.e. our donor pool) that best mimics the pre-intervention behavior of our treatment unit. An popular example of this is also found in [7] where the authors used SCM to model the effect of Califronia’s tobacco tax policy.
In our example, we would take a weighted average of our other 10 stores to form a synthetic control to compare against Seattle. Let’s quickly walk through what the math looks like in SCM.
SCM attempts to estimate the counterfactual Y_{t}^{N}, that is, the response of our treatment unit had the intervention never happened (i.e. the response of Seattle had it never received scanner guns). SCM estimates this counterfactual through a weighted average across the responses of the donor pool, as shown in Equation 4.3.
Y_{t}^{N} \approx \sum_{j=2}^{J+1} w_{j} Y_{jt} \tag{4.3}
The weights are calculated by finding the minimum distance between X_{1} (the pre-intervention characteristics of the treated unit) and X_{0}W (the pre-intervention characteristics of a control unit). This minimization is subject to two constraints: all weights must be greater than or equal to 0 and all weights must sum to 1. Once these weights are calculated, they are applied to the post-intervention responses of the control units. The distance between the treated unit and the synthetic control is then the estimated ATT.
In our analysis, we used pysyncon[8] to create our synthetic control. After preparing our data for it, we obtained the following weights.
1 0.028
2 0.000
3 0.000
4 0.000
5 0.297
6 0.000
7 0.000
8 0.525
9 0.149
10 0.000
Name: weights, dtype: float64As we can see, the closest city is city 8, followed by city 5, 9, and 1. The rest of the cities are not included in the weighted average. The plot of our synthetic control vs treated is found below in Figure 4.2.
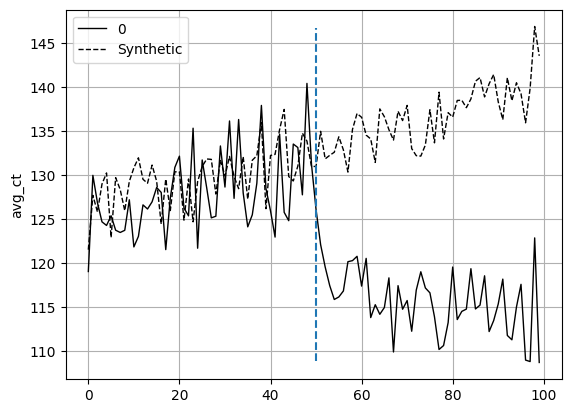
Our SC appears to follow the trajectory and variation of Seattle fairly well (in a real SCM, we’d want it better but this suffices for this analysis). As such, when the intervention occurs, we can estimate the ATT via the distance between these two units. The distance overtime between these two are shown in Figure 4.3. The ATT immediately follows below it.
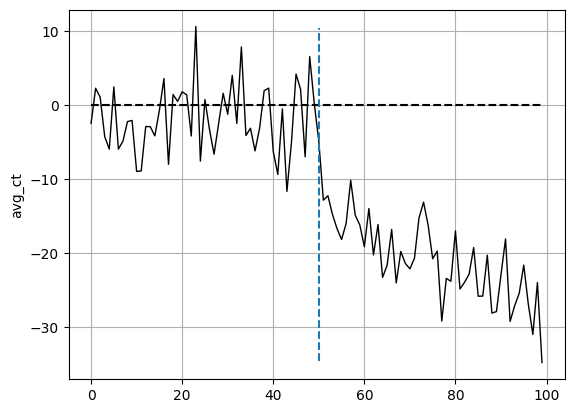
{'att': -20.67706963332358, 'se': 0.8177388666624705}From both Figure 4.2 and Figure 4.3, as well as the estimated ATT, the scanner guns appear to be a viable program for MW. Since we covered the effects on the operational efficiecny of this program in the previous experiment, we won’t go through it as detailed here. As mentioned earlier and as noticed in Figure 4.3, we’d want to aim for a better SC to avoid the huge spikes in distance from the treated unit pre-intervention.
Conclusion
In this post, we walked through how operation research principles can help us establish a foundational model on how the customer experience is for checkouts in MW. We calculated baseline metrics for how long it takes for customers to go through the queue and through checkout. We then analyzed the effects of a potential solution of using scanner guns to speed up the checkout process. We used DiD and SCM to calculate these causal effects as well as the potential changes in operational efficiency this program would provide. The next steps of this analysis in a proper business setting would include cost-benefit analysis, customer sentiment analysis from the pilot store, and if accepted, implementation protocols for the rest of the stores. Overall, this analysis provided a solid foundation on how causal inference can be utilized to enhance operational efficiency.
References
[1]
D. G. Kendall, “Stochastic processes occurring in the theory of queues and their analysis by the method of the imbedded markov chain,” The Annals of Mathematical Statistics, vol. 24, no. 3, pp. 338–354, 1953, doi: 10.1214/aoms/1177728975.
[2]
J. D. C. Little, “A proof for the queuing formula: L = w,” Operations Research, vol. 9, no. 3, pp. 383–387, 1961, doi: 10.1287/opre.9.3.383.
[3]
A. K. Erlang, “Solution of some problems in the theory of probabilities of significance in automatic telephone exchanges,” Elektrotkeknikeren, vol. 13, pp. 5–13, 1917.
[4]
D. Card and A. B. Krueger, “Minimum wages and employment: A case study of the fast-food industry in new jersey and pennsylvania,” The American Economic Review, vol. 84, no. 4, pp. 772–793, 1994.
[5]
D. B. Rubin, “Estimating causal effects of treatments in randomized and nonrandomized studies,” Journal of Educational Psychology, vol. 66, no. 5, pp. 688–701, 1974.
[6]
A. Abadie and J. Gardeazabal, “The economic costs of conflict: A case study of the basque country,” American Economic Review, vol. 93, no. 1, pp. 113–132, 2003, doi: 10.1257/000282803321455188.
[7]
A. Abadie, A. Diamond, and J. Hainmueller, “Synthetic control methods for comparative case studies: Estimating the effect of california’s tobacco control program,” Journal of the American Statistical Association, vol. 105, no. 490, pp. 493–505, 2010, doi: 10.1198/jasa.2009.ap08746.
[8]
S. Fordham, pysyncon: a Python package for the Synthetic Control Method. (Dec. 2022). Available: https://github.com/sdfordham/pysyncon