dataframe: grades_all (1060795, 9)
dataframe: UIN_dta (154081, 30)
dataframe: admits_co (12, 7)
dataframe: admits_mj (22, 7)
dataframe: target_co_FR (12, 2)
dataframe: target_co_TR (9, 2)
dataframe: target_mj_AT_FR (42, 2)
dataframe: target_mj_AT_TR (42, 2)
dataframe: major_college (186, 3)
dataframe: course_college (278, 2)Introduction
Forecasting enrollment for individual classes is important for departments and colleges at universities. It allows them to properly prepare adequate resources for students, such as: hiring the right number of TAs, offering the correct number of sections for classes, and assigning classes to the proper lecture halls. Needless to say, forecasting accurately the number of students signing up for a particular class is of high interest and need. Additionally, if possible, understanding the driving factors behind why certain classes are more popular or which classes are the most variable semester-to-semester is of particular interest.
We demonstrate in this post the power of Bayesian forecasting, utilizing a two-part model. The first part forecasts the percent change in enrollment for the upcoming semester compared to the previous semester. The second part forecasts the percent change in percent share of total enrollment at Texas A&M University.
EDA
We begin our analysis by viewing the scope of the data we will be working with. Below is a print out of all dataframes offered to us.
The above output shows we have 10 dataframes to possibly work with, with the first two containing a fairly large amount of data. From this, we can gather that a lot of data preparation and cleaning may be necessary before proceeding with analysis and model creation. A good way to approach this is by viewing the dataframes individually and gaining an understanding of what each contains. Below is a head method call on the grades_all dataframe.
| UIN | Subject | Course_Number | Quality_Points | Course_Credits | Final_Grade | Course_Section | Status | TERM | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | EHRD | 374.0 | 12.0 | 3.0 | A | 599 | RW | 20213.0 |
| 1 | 1 | EHRD | 477.0 | 12.0 | 3.0 | A | 599 | RW | 20213.0 |
| 2 | 2 | MKTG | 409.0 | 9.0 | 3.0 | B | 599 | RW | 20213.0 |
| 3 | 3 | POLS | 206.0 | 12.0 | 3.0 | A | 510 | RW | 20213.0 |
| 4 | 3 | AGLS | 235.0 | 12.0 | 3.0 | A | 599 | RW | 20213.0 |
From the above output, we see that there are 9 columns of data. UIN is a unique identifier for each student on campus (annonymized). Each of the other columns appear to be self-explanatory. TERM refers to the year the class was taken and the last digit (furthest left before the decimal) is the indicator of fall or spring term (3 being fall and 1 being spring).
To get a better idea of how many grades we have by term, we can use the groupby method. The result is shown below.
TERM Final_Grade
20213.0 A 122510
B 68995
C 30641
D 6734
F 4389
I 858
Q 10932
S 16483
U 457
W 2869
X 1721
20221.0 A 114925
B 62317
C 28265
D 6157
F 3728
I 543
NG 6
Q 9584
S 9831
U 297
W 2103
X 236
20223.0 A 132700
B 69269
C 29699
D 6589
F 3870
I 606
IP 1
NG 17
Q 9447
S 16248
U 533
W 2109
X 93
20231.0 A 1305
B 261
C 51
D 5
F 18
I 1
Q 49
S 95
U 1
X 4
20233.0 A 112
B 6
F 1
IP 282307
Q 596
W 197
X 24
dtype: int64Taking a quick glance at the data, there appears to be a steady number of grades by term up till 2023. Spring 2023 appears to have very few grades in comparison to other terms. Fall 2023 picks back up with the number of grades, but most of them are IP (in progress).
We can proceed to viewing more of the dataframes, like the UIN_dta. The head method on the UIN_dta dataframe yields the below result.
| UIN | PROG_CURR | COLL_CURR | PROG_ADM | COLL_ADM | TERM_LAST | TERM_ADM | TERM_CHG | ADM | DEG_CURR | ... | CM_ADM | YEAR_CHG | SEM_CHG | CM_CHG | FLAG | TERM_TOCS | YEAR_TOCS | SEM_TOCS | MAJOR_TOCS | TO_CS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | BS-HRDV | ED | BS-HRDL | ED | 202231.0 | 201831.0 | 201911.0 | TR | BS | ... | 1.0 | 2019.0 | 1.0 | 1.0 | 0.0 | NaN | NaN | NaN | 0.0 | |
| 1 | 89768.0 | BS-VISL | PV | BS-VISL | PV | 202031.0 | 202031.0 | 202031.0 | FR | BS | ... | 1.0 | 2020.0 | 3.0 | 1.0 | 0.0 | NaN | NaN | NaN | 0.0 | |
| 2 | 89769.0 | BS-RLEM-RMO | AG | BS-RLEM | AG | 202031.0 | 201911.0 | 201911.0 | TR | BS | ... | 1.0 | 2019.0 | 1.0 | 1.0 | 0.0 | NaN | NaN | NaN | 0.0 | |
| 3 | 3.0 | BA-USLA-SEL | AT | BA-USLA-SEL | AT | 202331.0 | 202111.0 | 202111.0 | FR | BA | ... | 1.0 | 2021.0 | 1.0 | 1.0 | 0.0 | NaN | NaN | NaN | 0.0 | |
| 4 | 89770.0 | BBA-MISY | BA | BS-AGBL | AG | 202111.0 | 201731.0 | 201911.0 | FR | BBA | ... | 1.0 | 2019.0 | 1.0 | 1.0 | 0.0 | NaN | NaN | NaN | 0.0 |
5 rows × 30 columns
The UIN_dta dataframe contains 30 columns of data. This dataframe, like the grades_all dataframe, contains a UIN column (perhaps will be useful for mapping data points). Additionally, this dataframe contains many other useful additional features about students.
To get a general idea if enrollment is growing by semester, we can plot out a time series plot to see the change over time of new admits for each term. Below in Figure 2.1 we see this result.

The spikes appear to be during the fall terms, which makes sense since most students begin their college career in the fall. We can continue to investigate this area further in the analysis.
Proceeding with exploring the various dataframes, we can list out how many unique subjects there are from our grades_all dataframe. The results are shown below.
array(['EHRD', 'MKTG', 'POLS', 'AGLS', 'COMM', 'ITAL', 'MATH', 'FYEX',
'CHEM', 'BIMS', 'CHIN', 'HIST', 'SPMT', 'MGMT', 'BUSN', 'PHYS',
'CSCE', 'MEEN', 'ENGL', 'JAPN', 'PERF', 'SOCI', 'MMET', 'MSEN',
'STAT', 'PBSI', 'WGST', 'ATMO', 'ENGR', 'FINC', 'TCMG', 'WFSC',
'ECEN', 'ISEN', 'ENTO', 'HLTH', 'ARCH', 'URPN', 'GEOG', 'MUSC',
'ECON', 'NUTR', 'BIOL', 'FSTC', 'ACCT', 'PHIL', 'KINE', 'ANTH',
'SOMS', 'AGSC', 'ANSC', 'ESSM', 'RPTS', 'GEOL', 'COSC', 'PHLT',
'GENE', 'AGEC', 'AERO', 'ARTS', 'SCSC', 'NUEN', 'POSC', 'ALED',
'INTS', 'FILM', 'CVEN', 'BICH', 'NRSC', 'SCMT', 'NVSC', 'VIBS',
'ISTM', 'SCEN', 'VTPB', 'FREN', 'HORT', 'ASCC', 'RDNG', 'INST',
'MASC', 'CLEN', 'RELS', 'AFST', 'IDIS', 'ESET', 'JOUR', 'LING',
'OCNG', 'ASTR', 'EPSY', 'RUSS', 'PLPA', 'VIST', 'BMEN', 'OCEN',
'NURS', 'TEFB', 'TEED', 'SPAN', 'CLSC', 'CHEN', 'AGSM', 'CLAS',
'AREN', 'EDCI', 'BESC', 'AGCJ', 'ECMT', 'MXET', 'GERM', 'SENG',
'LAND', 'ENTC', 'HISP', 'PETE', 'MEFB', 'CARC', 'GEOS', 'AERS',
'RENR', 'BAEN', 'VTPP', 'ALEC', 'MLSC', 'MTDE', 'MEPS', 'DCED',
'GEOP', 'FIVS', 'PSAA', 'ITDE', 'IBUS', 'UGST', 'KNFB', 'EVEN',
'ASIA', 'ENDS', 'EPFB', 'SPED', 'ATTR', 'DDHS', 'HEFB', 'MODL',
'INTA', 'LMAS', 'ARAB', 'BEFB', 'BUSH', 'SEFB', 'LBAR', 'EDHP',
'EURO', 'MUST', 'VSCS', 'BESL', 'SYEX', 'VLCS', 'CLGE', 'CYBR',
'HHUM', 'HCPI', 'SSEN', 'MEMA', 'DHUM', 'RWFM', 'LDEV', 'PLAN',
'VIZA', 'MSCI', 'ECCB', 'ARSC', 'ITSV', 'HMGT', 'SABR', 'CLBA',
'NSEB'], dtype=object)Additionally, we can view the most popular courses by semester. Below, we list the top 10 courses from each term and subsequently rank them by largest to smallest over the entire time frame of our dataset.
| TERM | Subject | Course_Number | count | |
|---|---|---|---|---|
| 4097 | 20233.0 | ENGR | 102.0 | 5470 |
| 2857 | 20223.0 | ENGR | 102.0 | 5433 |
| 416 | 20213.0 | ENGR | 102.0 | 4963 |
| 4207 | 20233.0 | FYEX | 101.0 | 4904 |
| 2968 | 20223.0 | FYEX | 101.0 | 4827 |
| 3385 | 20223.0 | POLS | 207.0 | 4602 |
| 531 | 20213.0 | FYEX | 101.0 | 4511 |
| 948 | 20213.0 | POLS | 207.0 | 4464 |
| 4419 | 20233.0 | MATH | 140.0 | 4394 |
| 4634 | 20233.0 | POLS | 207.0 | 4167 |
| 1907 | 20221.0 | KINE | 199.0 | 4124 |
| 3134 | 20223.0 | KINE | 199.0 | 3982 |
| 702 | 20213.0 | KINE | 199.0 | 3952 |
| 2158 | 20221.0 | POLS | 207.0 | 3895 |
| 3935 | 20233.0 | CHEM | 119.0 | 3789 |
| 4390 | 20233.0 | KINE | 199.0 | 3757 |
| 262 | 20213.0 | CHEM | 119.0 | 3600 |
| 734 | 20213.0 | MATH | 140.0 | 3594 |
| 3168 | 20223.0 | MATH | 140.0 | 3553 |
| 2691 | 20223.0 | CHEM | 119.0 | 3481 |
| 2145 | 20221.0 | PHYS | 216.0 | 3362 |
| 3169 | 20223.0 | MATH | 151.0 | 2923 |
| 3893 | 20233.0 | BIOL | 111.0 | 2852 |
| 1468 | 20221.0 | CHEM | 120.0 | 2824 |
| 4420 | 20233.0 | MATH | 151.0 | 2761 |
From the table above, we can see that ENGR 102 appears to be the most popular course over all time and even continues to have a growth. FYEX is a first year experience course so it appears that many freshmen take the course.
The information above can be utilized even further, by seeing if there were ever any large discrepancies in the number of students between two semesters. Due to the large amount of data, we will focus on one subject to view. Below in Figure 2.2, we see the difference over time between two semesters (current semester class enrollment - past semester class enrollment).
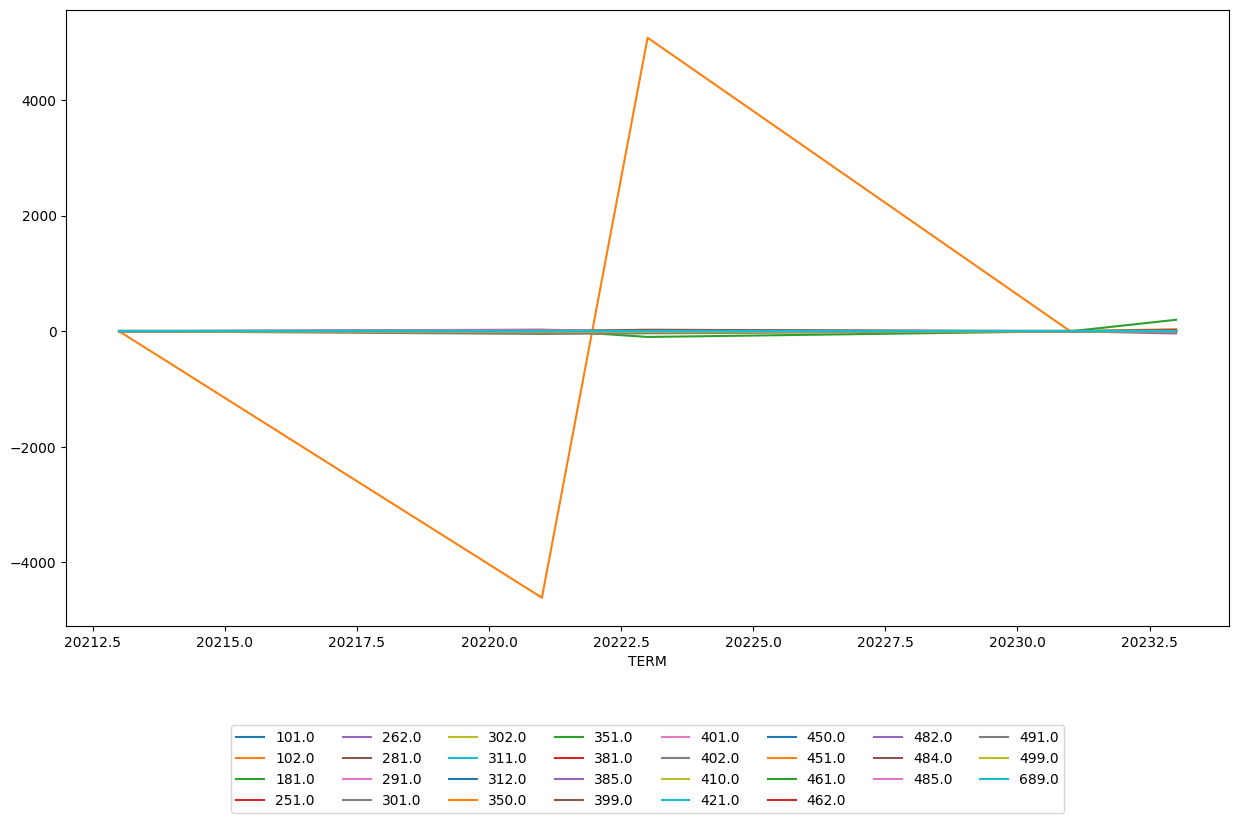
Such a large difference between two semesters, as shown in Figure 2.2, definitely merits a closer look to ensure that our graph properly calculated such a difference. Below is a tabular view of what we see above for ENGR 102.
| TERM | Subject | Course_Number | count | diff_term | |
|---|---|---|---|---|---|
| 949 | 20213.0 | ENGR | 102.0 | 4963 | 0.0 |
| 3460 | 20221.0 | ENGR | 102.0 | 353 | -4610.0 |
| 6098 | 20223.0 | ENGR | 102.0 | 5433 | 5080.0 |
| 8706 | 20233.0 | ENGR | 102.0 | 5470 | 37.0 |
For some reason, in spring 2022, there was a huge drop in enrollment for ENGR 102. One possible reason is that most of the people interested in such a course already took it in the fall to prepare for the next class that is only offered in the spring. We assume this hypothesis due to the elimination of ENGR 102 in the following spring. Perhaps this was noticed by university administration and to properly allocate resources, decided to drop the spring offering of ENGR 102.
This also presents a possible new challenge with our data. Assuming our above hypothesis is true, classes can be dropped from university offering due to lack of interest. We will need to account for this possible phenemenon in our model when we begin that process.
Figure 2.2 shows that for the most part, most classes are fairly consistent in their enrollment numbers (at least in ENGR), with exception to ENGR 102. ENGR 102, as we noted above, is consistently one of the largest classes on campus and thus we would have a larger amount of variation compared to smaller classes found in ENGR. We can generalize this approach of viewing variance of subjects by calculating the most variable classes based on their respective diff_term calculation that we performed above. The result of this is shown below in Figure 2.3
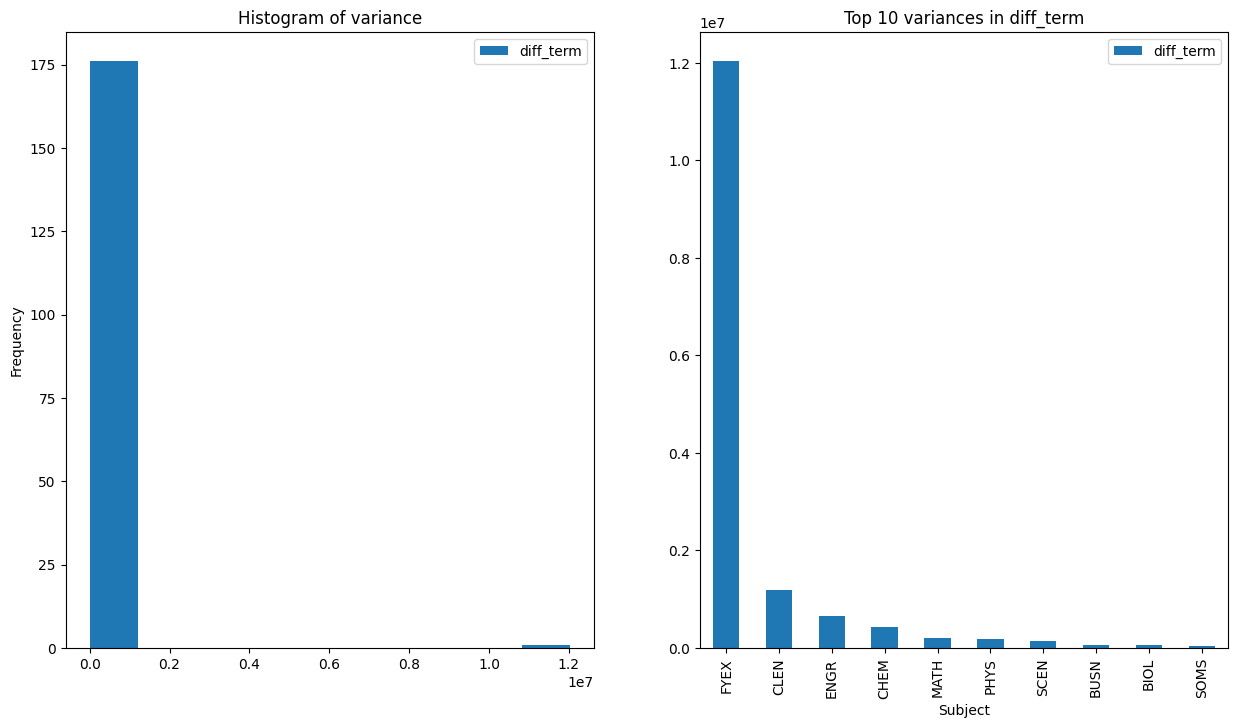
The left-hand panel in Figure 2.3 shows that the great majority of courses have the same variance (relatively speaking) with the exception to some very large variance outliers. These large outliers are probably from other large classes (like ENGR 102). The right-hand panel shows us which subjects are the highest ones. It is not suprising, once again, that many of these subjects were also part of the largest classes table.
Feature Engineering and Data Preprocessing
Now that we are somewhat familiar with the data we are working with and the possibilities of how the data can be modeled, we begin compiling the data into one large dataframe. Below is a beginning result of our mergers between dataframes.
| TERM | College | Subject | Course_Number | is_fall | count_students | count_freshmen | |
|---|---|---|---|---|---|---|---|
| 950 | 20213.0 | EN | ENGR | 102.0 | True | 4549 | 4549 |
| 2475 | 20221.0 | EN | ENGR | 102.0 | False | 278 | 81 |
| 4351 | 20223.0 | EN | ENGR | 102.0 | True | 4993 | 4945 |
| 6583 | 20233.0 | EN | ENGR | 102.0 | True | 4925 | 4869 |
From our sample taken from our newly merged dataframe, we have successfully important data points down to a class and term specific level. We will continue to modify this by adding and removing variables as we see fit. Please refer to the complete code found in the github repo for full information on how the complete data cleaning process was completed.
Forecasting Possibilities
As mentioned earlier in the analysis, the ultimate goal of this project is to accurately forecast to the enrollment of the next semester, down to the class level. To tackle this problem, we will first attempt to forecast for the entire university enrollment for the next term. The idea is that if we are confident in our ability to forecast for the entire university, we can continue to specify the model down to the class level. Essentially, we attempt a “simpler” forecasting problem first and will tackle the more complex one later. Figure 3.1 shows the total number of university enrollment over time.
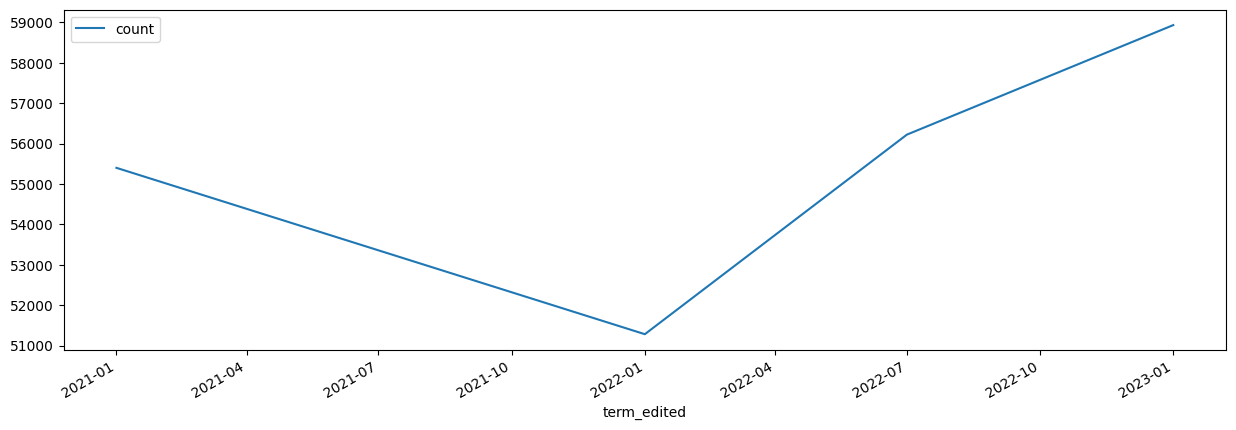
There appears to be a weird dip in the spring term of 2022 and then enrollment numbers return back to normal and then shows growth. As we can see, this forecasting problem will not be as straight forward due to the little amount of data we have (only 4 points of data). Additionally, this point at the beginning of spring 2022 seems to be an “outlier” in terms of the natural trend and growth of the university. Generally speaking, university enrollment grows (even if at a small rate) or at least remains fairly consistent (at least at large and well-known universities such as TAMU).
In forecasting problems such as this one, it is best to use datasets that are consistent and evenly spaced. Due to the irregular nature of the decrease in spring term of 2022, we will eliminate this point from the dataset and consequently, remove other data points associated with spring term. While the act of removing data points is risky due to the value of the information, to remain consistent and to simplify our model a bit, we will proceed with only forecasting for fall term enrollment. An example dataframe with these data points are provided below.
| TERM | count | |
|---|---|---|
| term_edited | ||
| 2021-01-01 | 20213.0 | 55400 |
| 2021-02-01 | 20223.0 | 56222 |
| 2021-03-01 | 20233.0 | 58933 |
Ignoring the term_edited column (created for ease of modeling), we see that we have 3 fall terms to use for our model. If we were to perform a train-test split on this data, this would mean that we would be left with 2 data points to train and 1 to predict. This is a fairly small training size to use and to have great confidence in what our next fall semester enrollment number would be.
To demonstrate this, we fit an ARIMA(0,0,0) model to predict 2023 fall enrollment using 2021 and 2022 as training data. Below are the results of our model.
SARIMAX Results
==============================================================================
Dep. Variable: count No. Observations: 2
Model: ARIMA Log Likelihood -14.875
Date: Fri, 31 May 2024 AIC 33.750
Time: 21:04:42 BIC 31.136
Sample: 0 HQIC 28.284
- 2
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const 5.581e+04 291.391 191.533 0.000 5.52e+04 5.64e+04
sigma2 1.694e+05 9.06e+07 0.002 0.999 -1.77e+08 1.78e+08
===================================================================================
Ljung-Box (L1) (Q): 2.00 Jarque-Bera (JB): 0.33
Prob(Q): 0.16 Prob(JB): 0.85
Heteroskedasticity (H): nan Skew: 0.00
Prob(H) (two-sided): nan Kurtosis: 1.00
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).Predicted number of students for fall 2023: 55811
Actual number of students for fall 2023: 58933The model, all things considered, performed fairly well at prediction! In the grand scheme of college enrollment, being off by approximately 3000 students is not bad. However, this model is a very simplified approach to our problem. We still need a model to predict the enrollment down to specific class level.
One possible way we can enhance our model is to go from tackling the problem head on to viewing it from a different perspective. Instead of forecasting the exact number of students on campus and then figuring out how to forecast enrollment for each class, we can predict the rate of change between semesters. While this approach would reduce our training data in half due to needing to calculate rate of change between semesters, this approach allows us a more flexible model because we can incorporate prior data. Essentially, this approach allows for a more natural Bayesian workflow to solving this problem.
Below is a table that shows the percent change in enrollment between semesters. We see that from 2021-2022, TAMU saw about a 1.5% increase in enrollment and from 2022-2023, TAMU saw about a 4.8% increase in enrollment. Do we believe this trend will continue? What do we believe to be a viable estimate for percent change between semesters? Tackling this problem using Bayesian methodology allows us gather good inference and possibly have more accurate predictions by using prior information and updating it with our data.
| temp_year | total_enroll | is_fall_2 | pct_change_enroll | |
|---|---|---|---|---|
| 0 | 2021.0 | 55400 | True | NaN |
| 2 | 2022.0 | 56222 | True | 1.483755 |
| 4 | 2023.0 | 58933 | True | 4.821956 |
Bayesian Modeling
To continue with our analysis, we add a Bayesian twist to it by deciding on a prior belief of percent change in enrollment. For our analysis (and from a brief Google search), we say that the percent change in enrollment between semesters is likely to be normally distributed with some mean \mu and some variance \sigma^{2}. Normally, in frequentist approaches, we would set \mu and \sigma^{2} by finding the MLE of each from our data and proposing that as our findings. In our Bayesian approach, we place uncertainty on these parameters by assigning each a prior distribution to express our beliefs of each parameter. For our analysis, we will assume the following distributions for \mu and \sigma^{2}.
\mu \sim N(0.03, 0.02)
\sigma \sim HN(0.02)
We propose that \mu is normally distributed with mean = 0.03 and sd = 0.02 with our \sigma being distributed in a half-normal distribution with parameter 0.02. With these priors, we believe that on average, the percent change in enrollment increases about 3% YoY. However, to express our uncertainty about this value, we use a wider sd of 0.02. Utilizing priors allow us to incorporate more data into our model while also allowing the model to vary due to our uncertainty of our prior beliefs.
Now that we have set our priors, we setup our Bayesian model using numpyro to perform our analysis. We use a NUTS sampler with 100 burn-in samples and 3000 MC samples. Below are the results of our sampling.
Model 1: Overall pct_change in Enrollment
mean std median 5.0% 95.0% n_eff r_hat
mu 0.02 0.01 0.02 0.00 0.04 682.95 1.00
sigma 0.01 0.01 0.01 0.00 0.03 596.88 1.00
Number of divergences: 62Training our model on just the percent change between 2021-2022 fall terms, we see our model has shifted the mean of our parameter \mu from 0.03 to 0.02. Additionally, our sd shrunk as well from 0.02 to 0.01. Our r_hat values of 1.00 and high n_eff scores are good indicators that our model achieved stationarity and good mixing. To continue to confirm that our model has good MCMC diagnostics, we view the trace plots for each of our parameters of interest (see Figure 4.1).
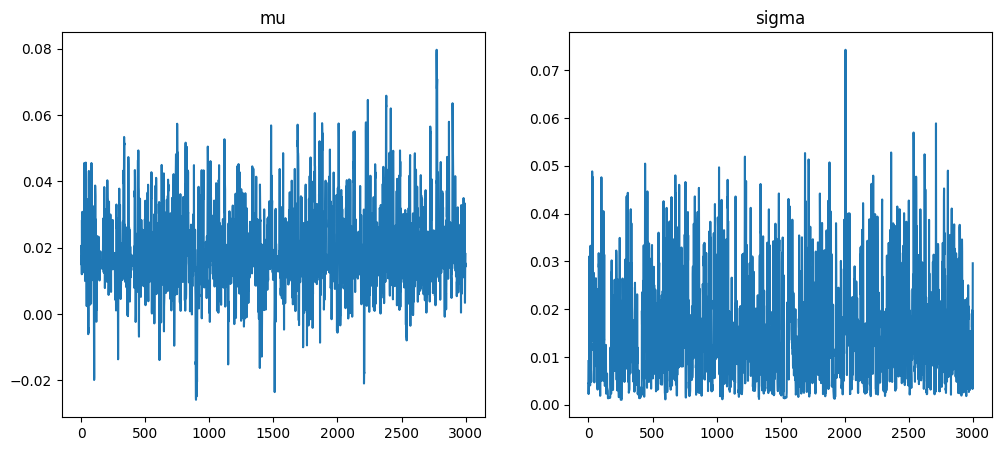
Figure 4.1 shows that our sampler mixed well and converged well, as both plots don’t appear to get stuck in any one particular region for too long.
Figure 4.2 below shows how our prior has been updated using the MAP estimates from our sampler. We see visually what we noticed in the table above, that our posterior became more peaked and shifted left about the x axis.
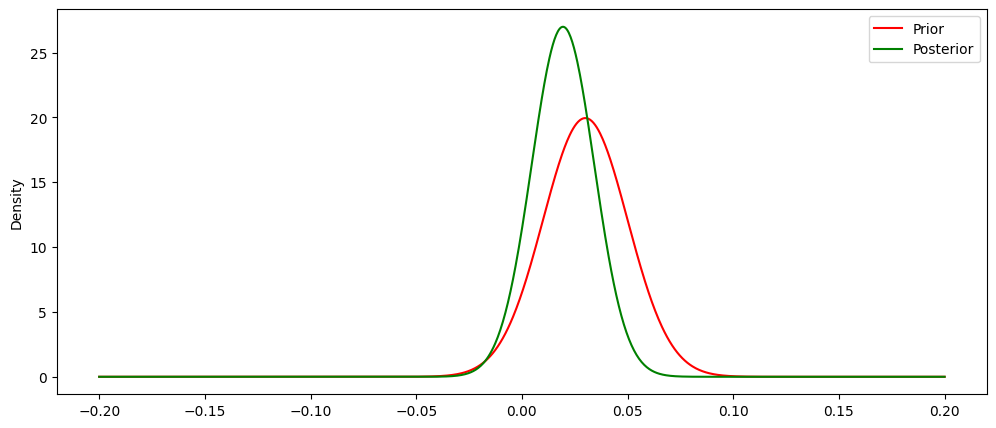
While Figure 4.2 is informative in showing how the MAP values update our prior, the power of Bayesian analysis comes from viewing the entire distribution of each parameter of interest and subsequently using those distributions to provide a predictive distribution, or posterior predictive distribution from which we can gather inference and make forecasts. Below in Figure 4.3 we see the complete distributions for each parameter of interest.
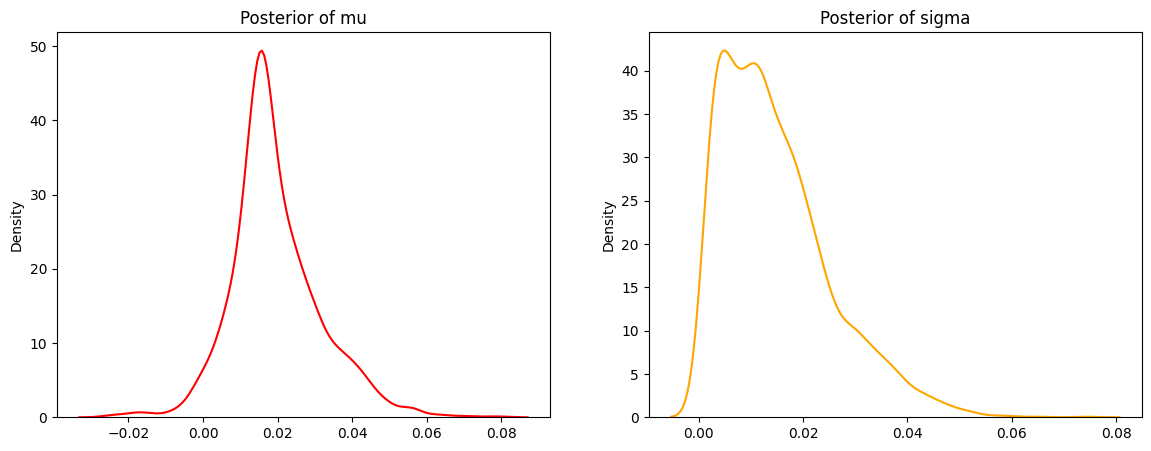
Figure 4.3 shows that our mu distribution still appears to be approximately normal, centered around 0.02. Our posterior of sigma is less peaked (almost bimodal) but is generally centered around 0.01. Our mu distribution shows that while it is most likely that we have an increase of student enrollment around 2% for this upcoming year, it is within reasonable probability that we could see no increase (eg 0% change). We can use 95% credible intervals to demonstrate what plausible values are within 95% probability for each parameter or interest.
95% CI for mu: (-0.001442579022841527, 0.046437517087906624)95% CI for sigma: (0.0015739109367132187, 0.04049663208425045)Our 95% CI for mu shows that within our 95% probability range, we could possibly see a decrease in student enrollment (be it a small one), but that the majority of our 95% CI includes positive values, meaning we would more than likely see some kind of increase for the next fall term.
Posterior Predictive Distribution (% Change in Enrollment)
As mentioned previously, we can now make predictions utilizing our posterior distributions. This is done by integrating out all of our parameters of interest (see Equation 4.1).
p(\overset{\sim}{y}|y_{1}...y_{n}) = \int_{\Theta} p(\overset{\sim}{y}|\theta)p(\theta|y) \tag{4.1}
What Equation 4.1 says is that in order for us to derive the posterior predictive distribution, integrate across all possible parameters of interest (in our case, mu and sigma) to derive a single distribution, conditioned upon our observed data. Our resulting posterior predictive distribution is found in Figure 4.4.
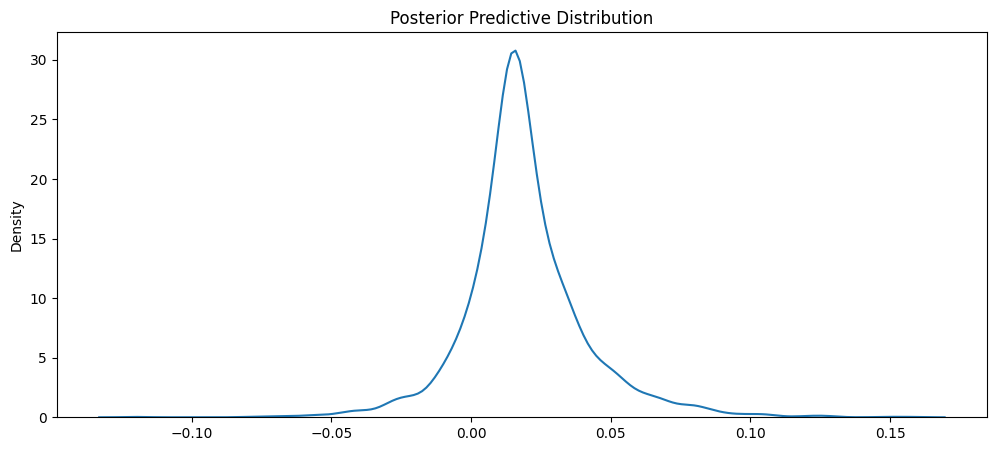
Mean of PPD: 0.01907617971301078895% CI of PPD: (-0.023650801740586758 , 0.07064365874975921)Our posterior predictive distribution is centered around 2% still but appears to be a wider distribution. This is because of our wider interval with our sigma distribution. Nonetheless, it is still an approximately normal distribution centered around 2% with corresponding 95% CI (or PI in this case) stating that with 95% probability the percent change in enrollment for the upcoming fall term will be between -2% and 7%. While this interval may be wider than desired, for utilizing only one training point of data and our weakly informative prior, it is a sufficient resource in predicting our fall enrollment for TAMU.
To make specific predictions using this distribution, we can utilize the MAP for a point estimate and the 95% CI for a range of predictions. Those results are shown below.
Bayesian Prediction of Enrollment: 57346
Actual Enrollment: 5893395% Prediction Interval for Enrollment: (55098, 60158)As we can see, our Bayesian prediction performed much better than our ARIMA model (granted it was a (0,0,0) model). Additionally, our 95% PI captures the actual value for fall 2023 enrollment at TAMU. As our model continues to receive more data, it will be able to shrink its PI range and have more precise predictions for our forecasts. Nonetheless, we have a viable first model at predicting enrollment at TAMU.
More exploration (For enhanced Bayesian Modeling)
While the above model successfully performed better than our “frequentist” approach, it still has not accomplished our ultimate goal of forecasting down to the classroom level. How can we utilize our first model as a viable resource to build a second model that can forecast down to the classroom level?
The question to explore now is “do we believe that the percent share of enrollment by class varies or is relatively constant?”. Essentially, if we discover that classes are generally consistent in how much percent of enrollment they take each fall term, then we can build a model that forecasts from our first model and utilizes class specific information to predict its percent share of enrollment. For example, suppose we have an intro level math class that for 3 fall terms had percent share of enrollment of: 2%, 3%, 4%. Utilizing our first model that predicts the entire university enrollment, we can generate a posterior predictive distribution that can predict the percent change in percent share of enrollment and multiply that change in value by the first predicted value (total university enrollment) to get a class specific enrollment value. Equation 4.2 shows the more pretty math behind this intuition.
\text{class level enrollment} = (\text{LY } \% \text{ enrollment} * (1 + \% \text{ change in enrollment})) * (\text{forecasted enrollment}) \tag{4.2}
Below is an example table of the data we will utilize to forecast percent share of total enrollment by class.
| Subject | Course_Number | is_fall | year | count_students | pct_of_enroll | |
|---|---|---|---|---|---|---|
| 815 | AERS | 101.0 | True | 2021 | 250 | 0.004513 |
| 5784 | AERS | 101.0 | True | 2022 | 293 | 0.005211 |
| 8394 | AERS | 101.0 | True | 2023 | 339 | 0.005752 |
| 821 | AERS | 105.0 | True | 2021 | 607 | 0.010957 |
| 5790 | AERS | 105.0 | True | 2022 | 589 | 0.010476 |
We can build out our formula from Equation 4.2 by creating a new column in our full dataframe to calculate the percent change in percent share of enrollment. Below is an example of this using an intro math class (MATH 140) at TAMU (see last column).
| College | Subject | Course_Number | is_fall | count_students | count_freshmen | count_sophomore | count_junior | count_senior | target_fresh_adm | ... | con_over_target | con_over_count_fresh | year_adm | count | yr_count | pct_share | pct_class_share | total_enroll | pct_of_enroll | pct_enroll_yoy | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 107 | AT | MATH | 140.0 | True | 3594 | 3190 | 294 | 72 | 38 | 2650 | ... | 0.953962 | 0.792476 | 2021 | 4158 | 16207 | 0.256556 | 0.196829 | 55400 | 0.064874 | NaN |
| 5049 | AT | MATH | 140.0 | True | 3552 | 2975 | 412 | 114 | 51 | 2650 | ... | 0.909057 | 0.809748 | 2022 | 3924 | 15956 | 0.245926 | 0.186450 | 56222 | 0.063178 | -0.026136 |
| 7656 | AT | MATH | 140.0 | True | 4392 | 3744 | 456 | 139 | 53 | 2650 | ... | 0.961887 | 0.680823 | 2023 | 4076 | 17415 | 0.234051 | 0.214987 | 58933 | 0.074525 | 0.179606 |
3 rows × 26 columns
And another example of an intro aerospace course (AERS 101).
| College | Subject | Course_Number | is_fall | count_students | count_freshmen | count_sophomore | count_junior | count_senior | target_fresh_adm | ... | con_over_target | con_over_count_fresh | year_adm | count | yr_count | pct_share | pct_class_share | total_enroll | pct_of_enroll | pct_enroll_yoy | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 815 | EN | AERS | 101.0 | True | 250 | 243 | 5 | 1 | 1 | 3250 | ... | 0.920000 | 12.304527 | 2021 | 4871 | 16207 | 0.300549 | 0.014994 | 55400 | 0.004513 | NaN |
| 5784 | EN | AERS | 101.0 | True | 293 | 286 | 7 | 0 | 0 | 3250 | ... | 1.110154 | 12.615385 | 2022 | 5240 | 15956 | 0.328403 | 0.017924 | 56222 | 0.005211 | 0.154865 |
| 8394 | EN | AERS | 101.0 | True | 339 | 329 | 9 | 0 | 1 | 3250 | ... | 1.052000 | 10.392097 | 2023 | 5263 | 17415 | 0.302211 | 0.018892 | 58933 | 0.005752 | 0.103773 |
3 rows × 26 columns
Another thing we notice about these classes is an obvious one: they’re different sizes! However, we know that they aren’t all unique in their own size. We can bucket these classes into arbitrary sizes (small, medium, large, etc.) to aid our model in identifying more specifically how certain class sizes vary on their percent change in percent share of enrollment. Below in Figure 4.5 shows a distribution of count of students for classes.
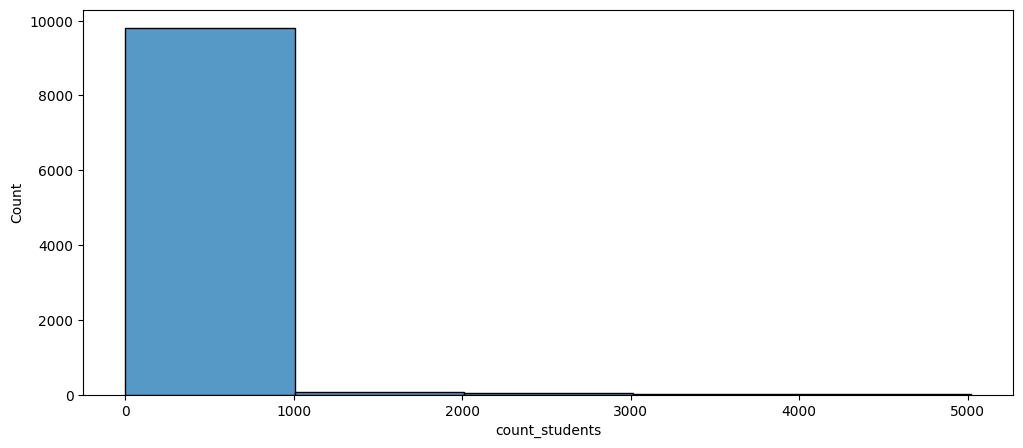
As we can see, the great majority of class sizes are found below 1000 students. We will need to take this into account when deciding how to divide our class size lines. While there are different ways of performing this in a more analytical way (i.e. segmentation analysis), we will arbitrarily decide on these buckets based on our EDA (see github repo for full EDA code).
One plot that we will include in this post is found in Figure 4.6. This figure shows the distribution for percent change in percent share of enrollment for each of our arbitrarily selected class sizes.
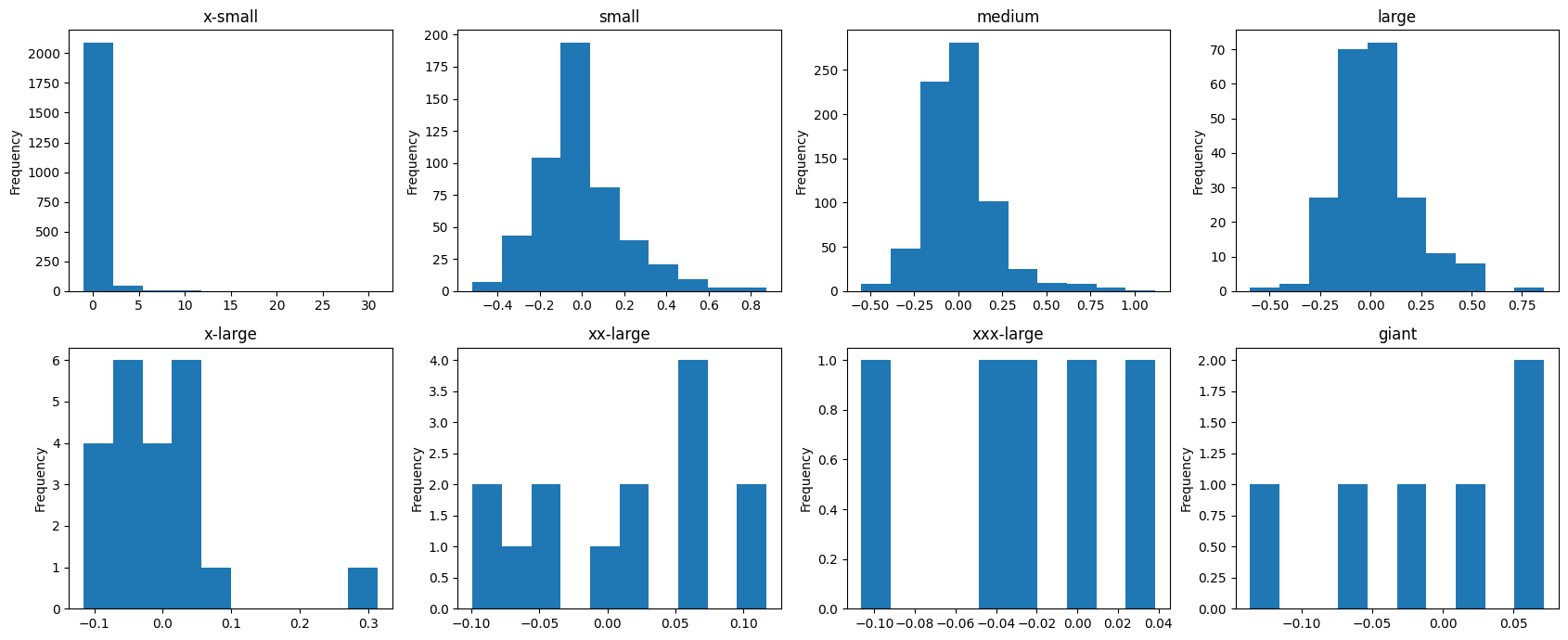
Figure 4.6 is telling in many ways. First, x-small classes are generally non-variable with a few large outliers (this also is acceptable because a x-small class can double in size fairly easily). Small, medium, and large classes are approximately normal in their distribution because these are the class sizes with the most observations (kind of like a fun way of seeing the CLT). All other larger classes appear almost uniform in their distributions due to their small respective sample sizes.
Model 2: Bayesian Hierarchical Model (class size)
As noted in some of the EDA above, the effects of each class size vary. While they are different, they aren’t completely different (as noted in Figure 4.6). To account for each class size effect individually, we utilize a hierarchical model to allow each class size to pull from a common distribution but to allow their respective effects to take update our prior beliefs. Below is the mathematical representation of our hierarchical model.
\theta \sim N(\mu_{j}, \sigma_{j})
\mu_{j} \sim N(0, 0.2)
\sigma_{j} \sim HN(0.2)
Modeling it this way essentially allows our parameter of interest, \theta to account for between-group variability based on the \mu_{j} and \sigma_{j} values while each respective \mu{j} and \sigma_{j} accounts for the within-group variability. This kind of flexibility will allow our model to predict down to specific classes based on the corresponding class size. After fitting our model to the data, we obtain the below results.
mean std median 5.0% 95.0% n_eff r_hat
class_mu[0] 0.13 0.02 0.13 0.09 0.17 3864.53 1.00
class_mu[1] 0.12 0.02 0.12 0.09 0.16 4569.29 1.00
class_mu[2] 0.09 0.01 0.09 0.07 0.12 5660.38 1.00
class_mu[3] 0.11 0.02 0.11 0.07 0.15 5829.37 1.00
class_mu[4] 0.08 0.04 0.08 0.01 0.15 2455.60 1.00
class_mu[5] 0.02 0.02 0.02 -0.01 0.05 3977.78 1.00
class_mu[6] -0.03 0.04 -0.03 -0.09 0.03 1414.55 1.00
class_mu[7] 0.01 0.05 0.01 -0.06 0.09 2553.92 1.00
class_sigma[0] 1.22 0.02 1.22 1.19 1.25 5456.28 1.00
class_sigma[1] 0.55 0.02 0.55 0.53 0.58 2663.55 1.00
class_sigma[2] 0.44 0.01 0.44 0.42 0.46 3291.40 1.00
class_sigma[3] 0.36 0.02 0.36 0.33 0.38 2453.18 1.00
class_sigma[4] 0.24 0.03 0.23 0.19 0.28 2273.90 1.00
class_sigma[5] 0.07 0.01 0.07 0.05 0.09 2460.03 1.00
class_sigma[6] 0.08 0.04 0.07 0.03 0.13 965.08 1.00
class_sigma[7] 0.13 0.05 0.12 0.07 0.19 2506.08 1.00
mu 0.05 0.11 0.05 -0.13 0.23 3127.97 1.00
sigma 0.37 0.06 0.36 0.27 0.46 2508.96 1.00
Number of divergences: 0class_mu[0] represents the distribution for class size x-small while class_mu[7] represents class size giant. All other class sizes are between these ranges in ascending order (x-small to giant). Additionally, our n_eff and r_hat scores show that our sampler performed very well and that each distribution achieved sufficient stationarity and good mixing. To confirm our results using visuals, we can look at Figure 4.7.
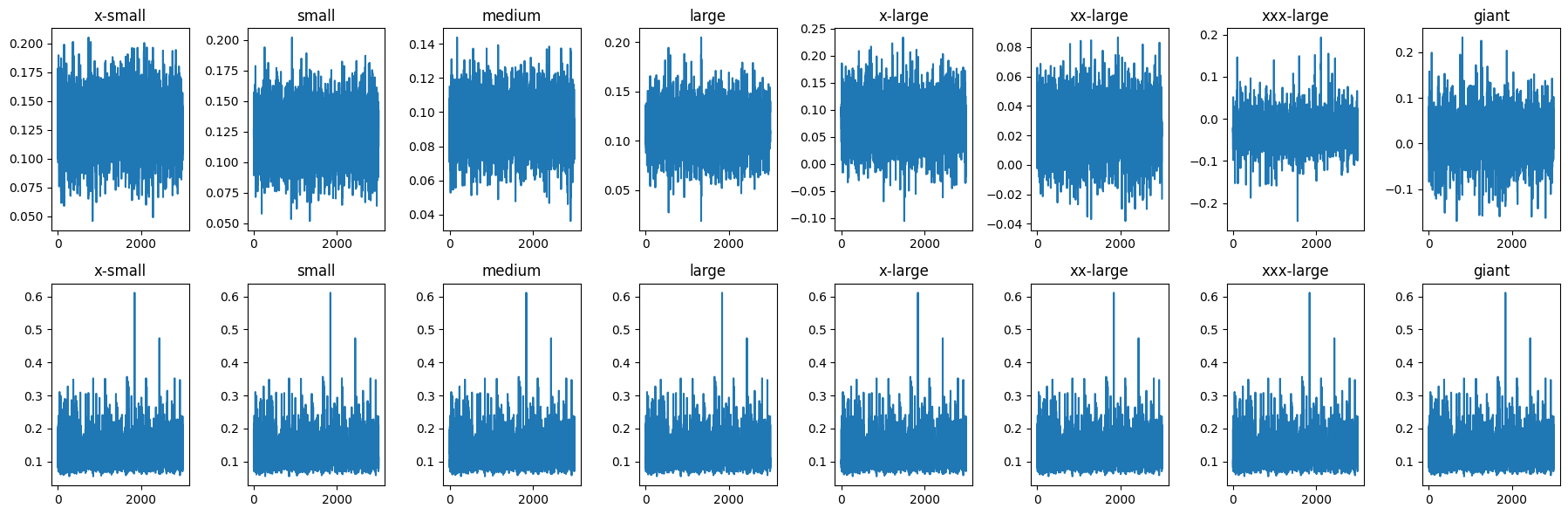
From Figure 4.7, we see that each mu and sigma trace plot per class appear to have good mixing and acceptable stationarity. Now that we have checked our MCMC diagnostics, we can begin exploring the generated posteriors from our model. Figure 4.8 shows respective distributions for class size’s mu parameter.
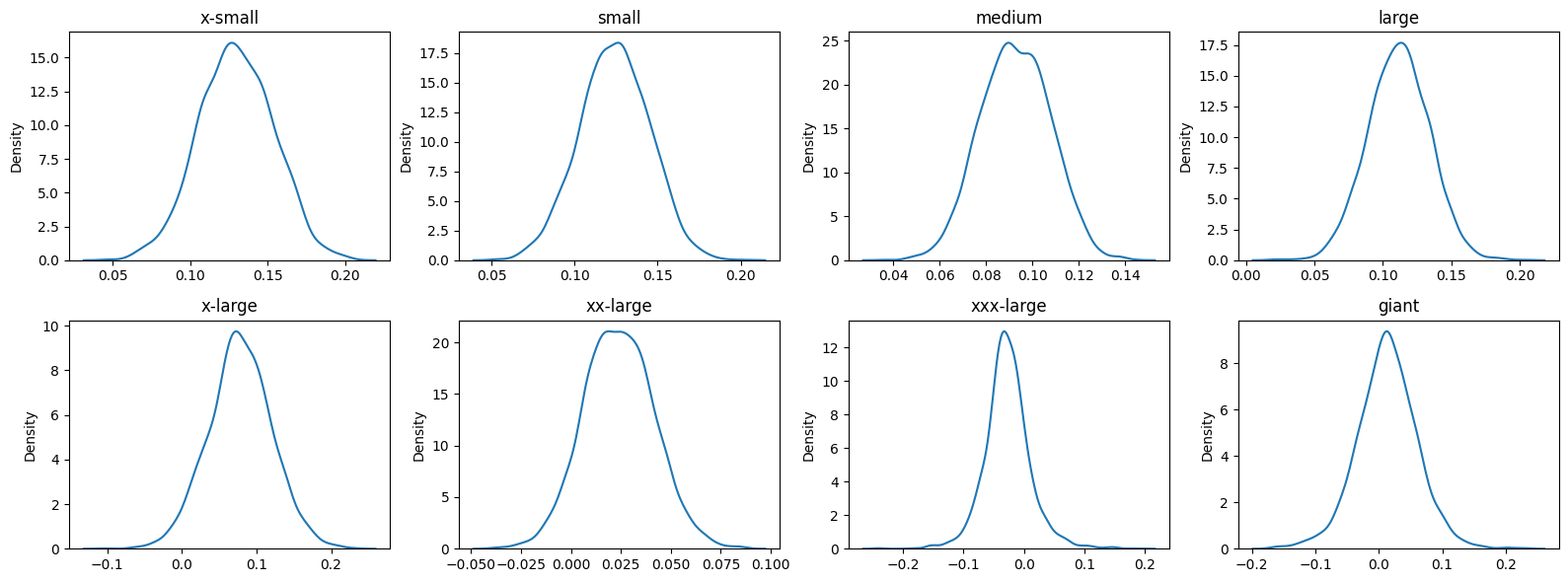
Figure 4.8 shows each class size mu parameter is approximately normally distributed. It is interesting to note where each distribution is centered. X-small is centered around .13 whereas larger classes like xxx-large are more centered around 0. It appears the there is a higher chance for smaller classes to have an increase in percent change in percent share of enrollment, whereas larger classes don’t vary as much. Larger classes seem to stay most constant term by term, which is not too surprising. A similar plot for class size sigma parameter is found in Figure 4.9.
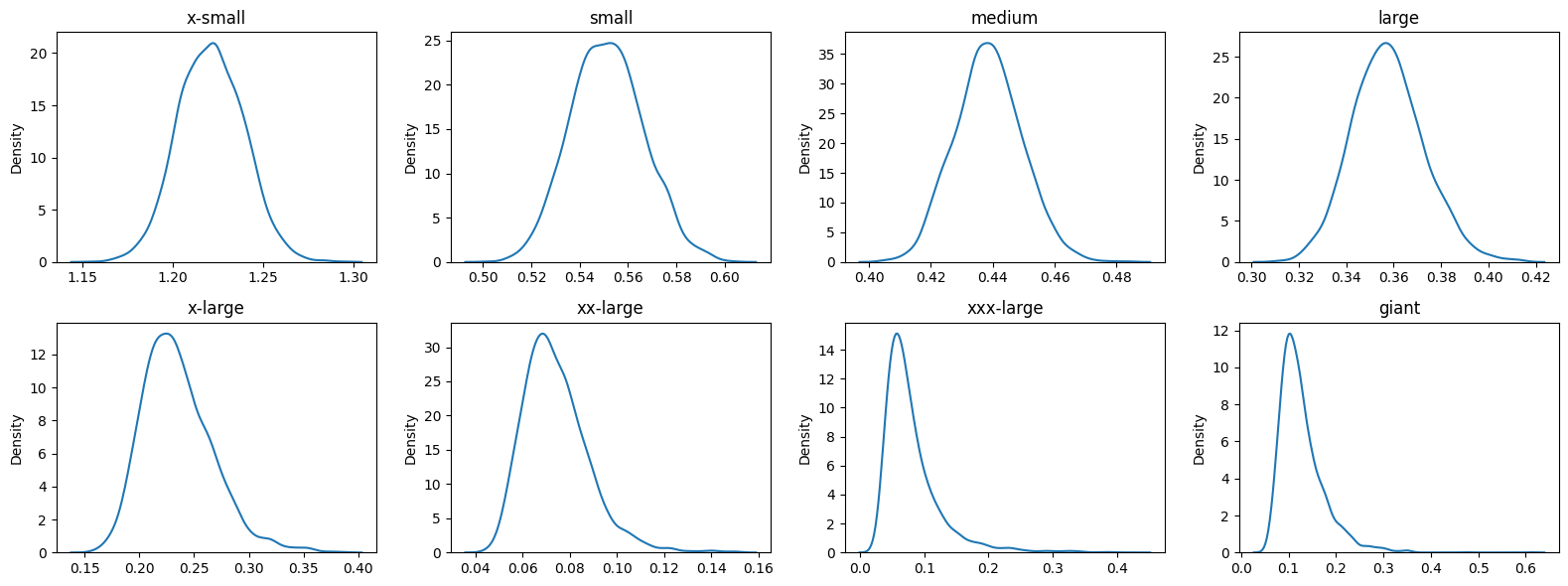
Once again, we notice that as the class size increases, the variability in sigma decreases.
Posterior Predictive Distribution (Hierarchical Model)
Just as we performed in the first model of this analysis, we will generate a posterior predictive distribution to make class specific predictions. Since we built a hierarchical model, we will generate 8 separate PPDs for each class size. Figure 4.10 shows the respective PPD for each class size.
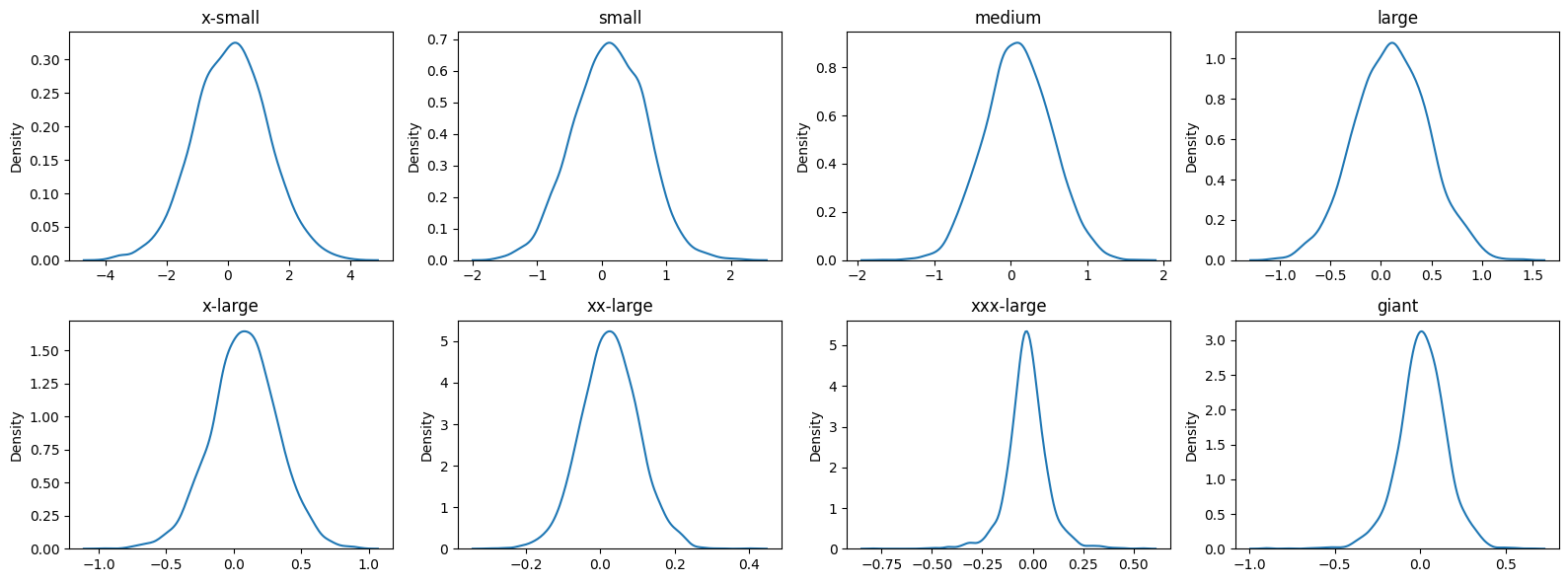
Figure 4.10 shows just how variable the smaller classes can be. While the x-small through medium classes are all relatively centered around 0 (possibly due to scale of x axis), the variation in their predictions are fairly wide, especially in x-small classes. However, this should not be too problematic as an x-small class of size 10, even doubling in size, would only be 20. More than likely 1 professor and 1 TA would still be sufficient for this class.
In contrast, we see that our larger classes do not have nearly as much predicted variability (a repeated theme we have mentioned a lot). This is good to know since these classes require the most resources. Since they appear to be reliably consistent, we can “trust” more in the predictions and know they will not be too far off from the usual.
For example, take the class MATH 140 at TAMU. It is considered an intro level math course that many students must take in order to progress in their respective majors. It is considered a xxx-large class due to its popularity. Below is a point prediction for this class.
Bayes Prediction for % change in pct_enroll: -0.027
True Value for % change in pct_enroll: 0.180The model, due to its MAP, incorretly predicted the percent change in percent share of enrollment. However, point estimates in continuous predictions are rarely ever correct and thus require an interval prediction to ensure that our model at least captures the value within the interval. Below is a 95% PI for MATH 140.
95% Prediction Interval for % change in pct_enroll: (-0.229, 0.179)As we can see, our interval would include the actual value (even if it is on the farthest outside). This indicates that the true value that occured is in fact a possibel anomaly. That is, it is a plausible value but is just not very likely. Nonetheless, because we used a Bayesian approach, we can probabilistically say that it is a possible value in the range of 95% probability.
In order to properly predict the actual count of student enrollment by class, as mentioned previously, we use Equation 4.2. Below is the predicted number of students, both point estimate and 95% PI.
Point Estimate for MATH 140: 3527
Actual Value for MATH 140: 439295% Prediction Interval for MATH 140: (2794, 4271)As we can see, the 95% prediction interval is not far off from the actual value. The missing values would be trivial in such a large class forecast (at least for allocating university resources). While this test case has been informative, we should test another class to ensure our model is not always facing possible anomalies. To do this, we will look at MATH 308. Below is the point prediction for MATH 308.
Bayes Prediction for % change in pct_enroll: 0.105
True Value for % change in pct_enroll: 0.051As we can see, this time our model is over estimating the point estimate for percent change in percent share of enrollment. Our model predicts about a 10% increase in percent share of enrollment when the actual 2023 value was about 5%. While the point estimate is incorrect, it is not too far off in terms of practical prediction. Below is the corresponding 95% PI and resulting predictions from the point estimate and the PI.
95% Prediction Interval for % change in pct_enroll: (-0.610, 0.832)Point Estimate for MATH 308: 990
Actual Value for MATH 308: 96795% Prediction Interval for MATH 308: (349, 1640)As mentioned above, our point estimate from a practical point of view is not too far from the actual value and would not have any major ramifications from a resource allocation point of view. Our 95% PI though, it quite wide. While it is slightly narrower than our 95% PI for MATH 140, it is still a very large range that would not be too useful for forecasting. Nonetheless, this model has proven to be very useful in predicting (especially from a practical point of view) the percent change in percent share of enrollment. Combined with the first model, we have created a system for forecasting class enrollment down to specific class levels.
Model 3: Bayesian Hierarchical Linear Model (college and class size)
While our Bayesian hierarchical model proved to be a useful model in our system for forecasting class enrollment, we believe we can do better given the amount of information we have. Another useful piece of information that we can utilize is college. Specifying to which college each class size pertains can help our model distinguish more clearly the percent change in percent share of enrollment for a specific class. Our model will then be an additive model, where we have two covariates (college and class size) predicting our response (% change in % share of enrollment). Below is the mathematical form of our model.
Y_{ijk} = X_{ijk}\beta_{jk} + \epsilon_{ijk}
\epsilon_{ijk} \sim N(0, \sigma^{2})
Y_{jk} \sim MVN(X_{jk}\beta_{jk}, \sigma^{2}I)
\beta_{j} \sim N(\mu_{m},\sigma_{m}^{2})
\beta_{k} \sim N(\mu_{t}, \sigma_{t}^{2})
\mu_{m} \sim N(0, 0.5)
\sigma_{m} \sim HN(0.5)
\mu_{t} \sim N(0, 0.5)
\sigma_{t} \sim HN(0.5)
After fitting our model to the data and using a NUTS sampler w/ 500 warmup and 5000 samples, we achieve the below results.
mean std median 5.0% 95.0% n_eff r_hat
class_beta[0] 0.03 0.04 0.03 -0.03 0.10 1825.25 1.00
class_beta[1] 0.05 0.04 0.04 -0.01 0.10 688.67 1.00
class_beta[2] 0.04 0.03 0.03 -0.01 0.07 752.82 1.00
class_beta[3] 0.03 0.02 0.03 -0.01 0.07 1153.19 1.00
class_beta[4] 0.03 0.03 0.03 -0.02 0.07 1733.09 1.00
class_beta[5] 0.02 0.03 0.02 -0.03 0.07 1545.40 1.00
class_beta[6] 0.02 0.03 0.02 -0.03 0.08 1703.07 1.00
class_beta[7] 0.02 0.03 0.02 -0.03 0.07 1596.52 1.00
class_int[0] 0.03 0.02 0.03 -0.00 0.07 517.34 1.00
class_int[1] 0.02 0.02 0.02 -0.01 0.05 1396.59 1.00
class_int[2] 0.01 0.02 0.01 -0.02 0.04 2576.21 1.00
class_int[3] 0.01 0.02 0.01 -0.02 0.04 2259.81 1.00
class_int[4] 0.01 0.02 0.01 -0.02 0.04 2348.81 1.00
class_int[5] 0.01 0.02 0.01 -0.02 0.04 2704.20 1.00
class_int[6] 0.01 0.02 0.01 -0.02 0.04 2207.97 1.00
class_int[7] 0.01 0.02 0.01 -0.02 0.04 1860.08 1.00
college_beta[0] 0.02 0.01 0.02 0.01 0.03 711.33 1.00
college_beta[1] 0.01 0.01 0.01 -0.01 0.03 1322.16 1.00
college_beta[2] 0.00 0.01 0.00 -0.02 0.02 647.16 1.00
college_beta[3] 0.01 0.02 0.01 -0.02 0.03 1262.88 1.00
college_beta[4] 0.00 0.02 0.01 -0.03 0.04 1269.12 1.00
college_beta[5] 0.00 0.03 0.01 -0.04 0.04 1430.99 1.00
college_beta[6] 0.00 0.03 0.01 -0.04 0.05 1733.26 1.00
college_beta[7] 0.00 0.03 0.01 -0.04 0.04 1146.67 1.00
college_beta[8] 0.01 0.03 0.01 -0.03 0.05 2263.37 1.00
college_beta[9] 0.01 0.03 0.01 -0.04 0.04 2195.16 1.00
mu_class 0.03 0.02 0.03 -0.01 0.07 844.81 1.00
mu_college 0.01 0.01 0.01 -0.02 0.03 915.74 1.00
mu_int 0.01 0.01 0.01 -0.00 0.03 1558.78 1.00
sigma 0.96 0.01 0.96 0.95 0.98 3696.71 1.00
sigma_class 0.03 0.02 0.02 0.00 0.06 456.18 1.00
sigma_college 0.02 0.02 0.01 0.00 0.04 407.22 1.00
sigma_int 0.01 0.01 0.01 0.00 0.03 348.40 1.00
Number of divergences: 131Our output for each beta appears to indicate that we have acheived stationarity and good mixing. To verify this visually, we can look at Figure 4.11.
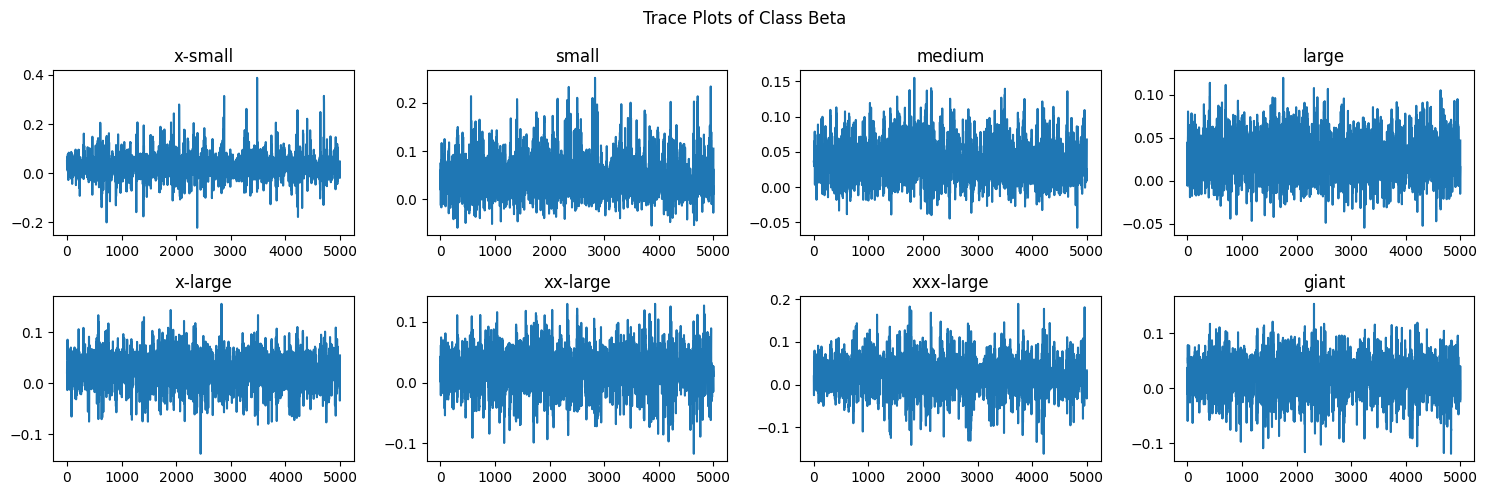
The betas for each class size level appear to be well mixed and stationary. To verify the betas for each college, we can look at Figure 4.12.
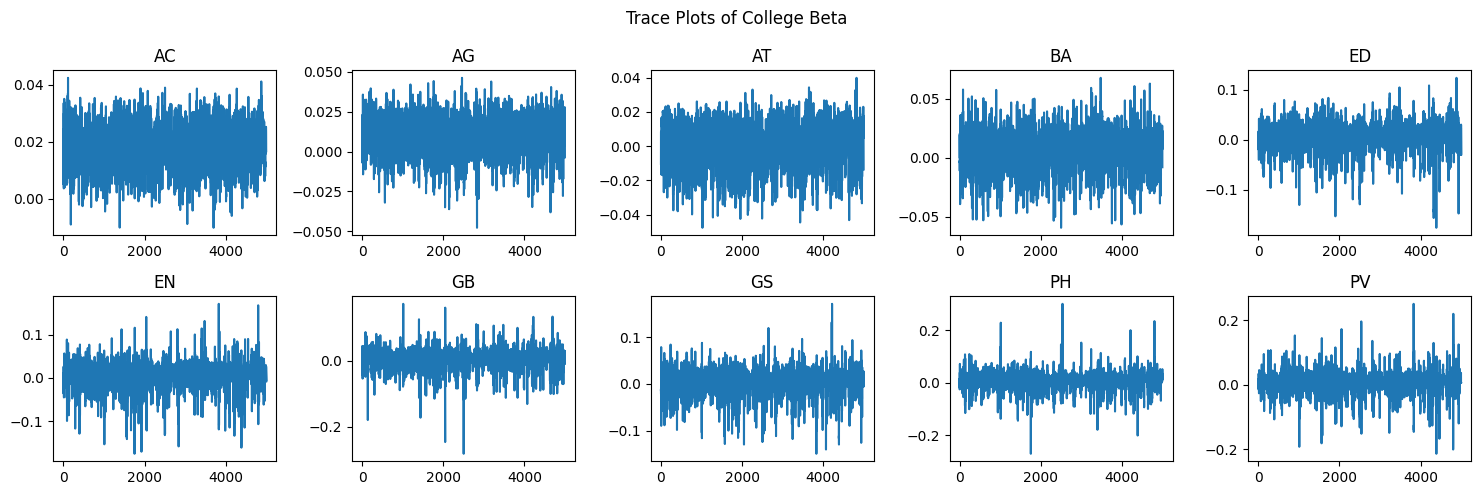
Just as with Figure 4.11, we can see that each college appears to have reached appropriate stationarity and mixing. Now that we have verified that our sampler functioned well, we can begin investigating the posterior distributions. Figure 4.13 shows the posterior distributions of each class size and Figure 4.14 shows the posterior distributions for each college.
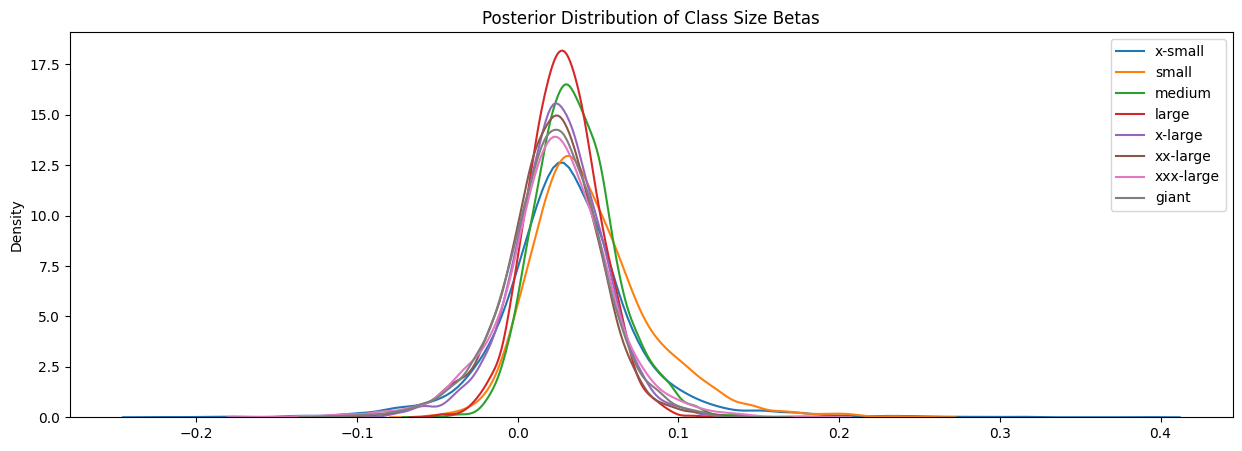
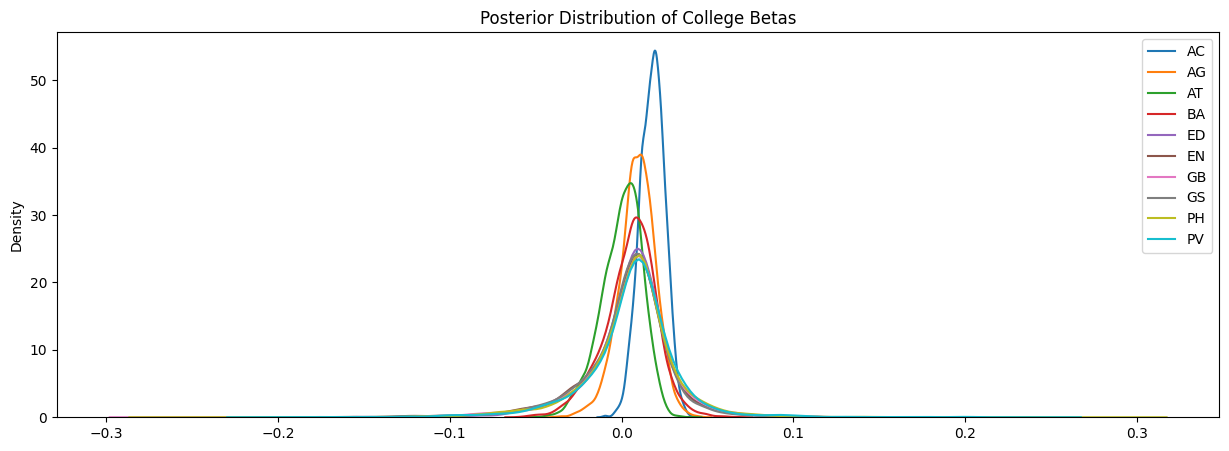
It is interesting to note that in both Figure 4.13 and Figure 4.14, we see that most of the distributions are relatively centered around the point. The distinguishing feature for each distribution is the respective spread.
Just as we performed for our first hierarchical model, we can perform predictions by generating a posterior predictive distribution (see Equation 4.1). We will first explore the predictions with this model for MATH 308 and compare it to our predictions from our first hierarchical model. The results are shown below.
Mean of pred_lm: 0.0403
95% PI of pred_lm: (-0.0108, 0.0907)
True value of pct_enroll_yoy: 0.0507
Predicted Number of Students: 932
95% PI of Number of Students: (886, 977)
True Number of Students: 967The very notable change in our prediction from our hierarchical linear model is that our PI range has shrunk significantly. Instead of the upper limit being close to .8, our upper limit of our 95% PI is approximately .09. That is a significant improvement! Our new hierarchical model also still contains the true value of percent change in percent share of enrollment. As we can see from above, our 95% PI for the predicted number of students is significantly better than before and would be of much better use practically for forecasting. We can perform this exercise again with predictions for MATH 140. Below are our results.
Mean of pred_lm: 0.0354
95% PI of pred_lm: (-0.0483, 0.1073)
True value of pct_enroll_yoy: 0.1796
Predicted Number of Students: 3751
95% PI of Number of Students: (3448, 4012)
True Number of Students: 4392We once again see a shrunken PI interval for this class. However, because the true percent change in percent enrollment was a large anomaly, our newly shrunken 95% PI does not capture our true percent change in percent share of enrollment. Nonetheless, the 95% PI can still be of practical use as it is not too far off from the true number of predicted students.
Conclusion
Our analysis showed that a good way to forecast student enrollment to a class specific level is well done using a Bayesian hierarchical linear model. Utilizing the information of class size and college provided the model a good way of approximating the percent change in percent share of enrollment. By approaching this forecasting problem from a percent change perspective, we demonstrated that these changes approximately follow a normal distribution, depending on the class size and college mixture. Additional data points should be investigated to determine if they would be viable additions to our model, as well as more thorough investigations on how to set priors and delineate between class sizes. Overall, we have proven that it is possible to forecast student enrollment down to the class level using Bayesian methods.